L06 · Tomasulo
L06 · Tomasulo
Topic: out-of-order · 46 pages
EECS 4340 Lecture 6 — Tomasulo's Algorithm

Announcements

Show slide text
Announcements
- Lab #5 next Monday
- Project #3
- Due: 25-Feb-26
- Project #4
- Due: proposal, 4-Mar-26
- More details in today’s class
- Mid-term exam
- 9-Mar-26
Readings

Show slide text
Readings
For today:
- H & P Chapter 3.4–3.6
- Design Space of Register Renaming Techniques, https://ieeexplore.ieee.org/abstract/document/877952
For next Wednesday:
- H & P Chapter 3.8–3.9, C.4–C.5
- Implementing precise interrupts in pipelined processors, https://ieeexplore.ieee.org/abstract/document/4607
- H & P Chapter 3.13
Recap: Scoreboard Scheduling

Simple Scoreboard Data Structures
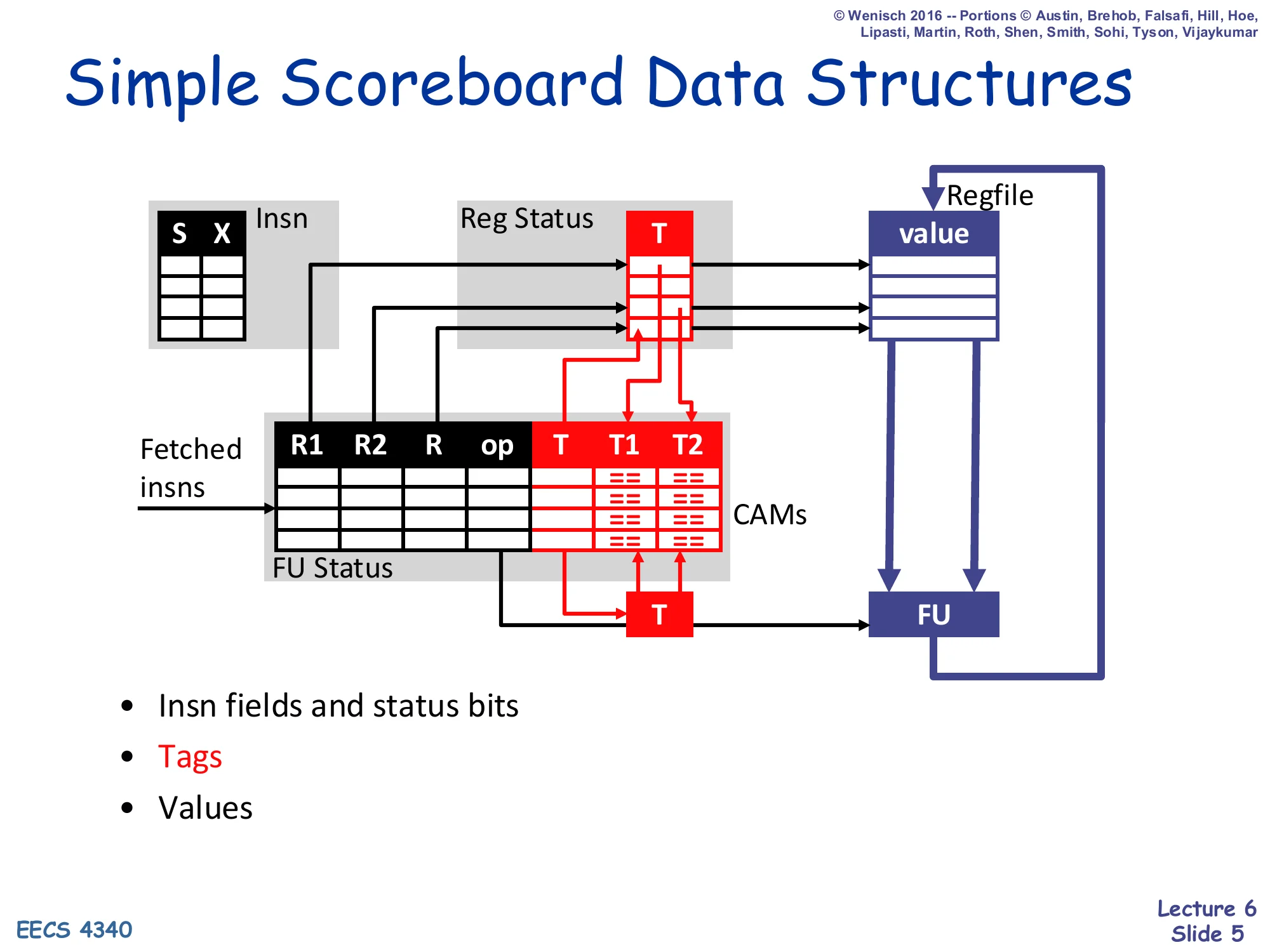
Show slide text
Simple Scoreboard Data Structures
- Insn fields and status bits (S, X)
- Tags — destination tag T in Reg Status, source tags T1/T2 in FU Status (CAMs)
- Values held in the regfile and forwarded to FU on issue
Structures shown: Insn table, Reg Status (T), FU Status (R1, R2, R, op, T, T1, T2), Regfile (value), FU.
This recap slide reminds you that the CDC 6600 scoreboard tracks instructions with three coupled tables. The Insn table just records per-instruction status bits (S = issued, X = executed). The FU Status table is the heart of the scoreboard: per functional unit it keeps source register names R1/R2, destination R, the opcode, the destination tag T, and the source tags T1/T2 — these last three are stored in CAMs so that when a writeback completes the matching tag entries can be cleared in parallel. The Reg Status table maps each architectural register to the tag of the FU currently writing it (or empty if none). Crucially, the scoreboard does not copy operand values into the FU table; values stay in the regfile and are read on issue. This is why scoreboarding suffers WAR hazards — a later writer cannot update the regfile until earlier readers have actually read it. Tomasulo will fix that on later slides by adding V1/V2 value copies inside reservation stations.
Scoreboard Pipeline

Show slide text
Scoreboard Pipeline
New pipeline structure: F, D, S, X, W
- F (fetch)
- Same as it ever was
- D (dispatch)
- Structural or WAW hazard ? stall : allocate scoreboard entry
- S (issue)
- RAW hazard ? wait : read registers, go to execute
- X (execute)
- Execute operation, notify scoreboard when done
- W (writeback)
- WAR hazard ? wait : write register, free scoreboard entry
- W and RAW-dependent S in same cycle
- W and structural-dependent D in same cycle
Scoreboarding splits the classical decode stage into in-order Dispatch and out-of-order issue (S). Dispatch enforces hazards that need program order: a structural hazard (no free FU/scoreboard slot) or a WAW hazard stalls the front end so later instructions cannot pass. Issue enforces RAW hazards: it waits (without blocking dispatch of independent instructions) until both source operands are produced, then reads the regfile and sends the instruction to execute. Writeback is where scoreboarding pays its WAR tax: a result must wait until every still-pending earlier reader has issued, because there are no operand copies. The two “same cycle” rules let a writeback unblock a dependent issue or a structurally-blocked dispatch in the same cycle, avoiding a one-cycle bubble. Memorize the stall-vs.-wait distinction: stall blocks the queue head, wait does not.
Scoreboard Dispatch (D)
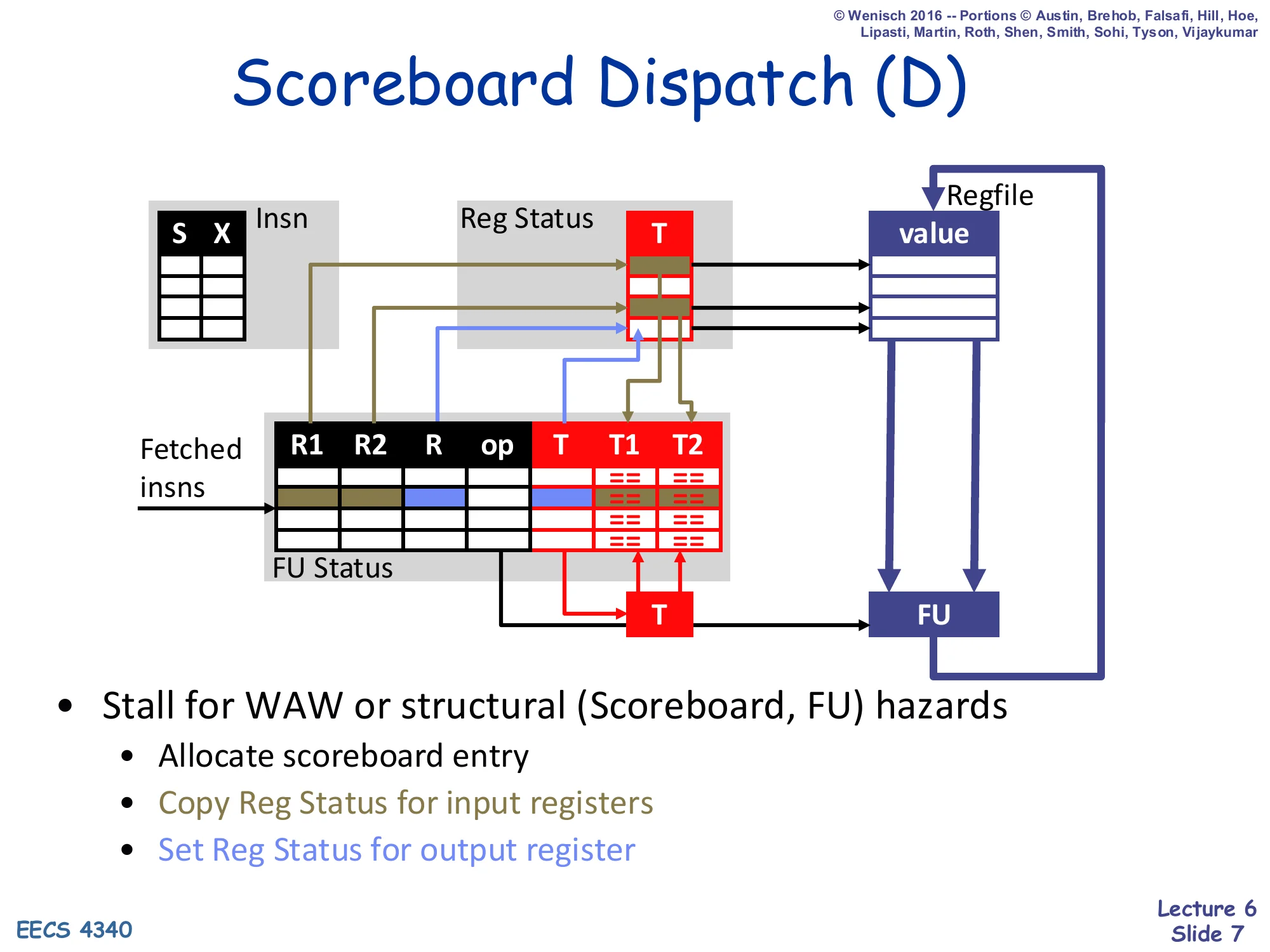
Show slide text
Scoreboard Dispatch (D)
- Stall for WAW or structural (Scoreboard, FU) hazards
- Allocate scoreboard entry
- Copy Reg Status for input registers
- Set Reg Status for output register
Dispatch is the in-order stage where the scoreboard binds an instruction to a functional-unit slot. It first checks two stall conditions: is the FU’s scoreboard entry already busy (structural hazard), and does another in-flight instruction already write the destination (WAW). If either is true the front end blocks because letting the instruction proceed would either overwrite live state or violate the architectural-register single-writer invariant. Once cleared, three writes happen in this cycle: (1) the scoreboard entry is allocated and the opcode/source/dest fields are filled, (2) the current tags for each input register are copied from Reg Status into the FU’s T1/T2 fields so that the issue stage can later watch for matching writebacks, and (3) the output register’s Reg Status entry is set to point at this FU, advertising to later instructions that they should wait for this producer. This last write is what makes the next instruction reading the same destination see the up-to-date producer tag.
Scoreboard Issue (S)
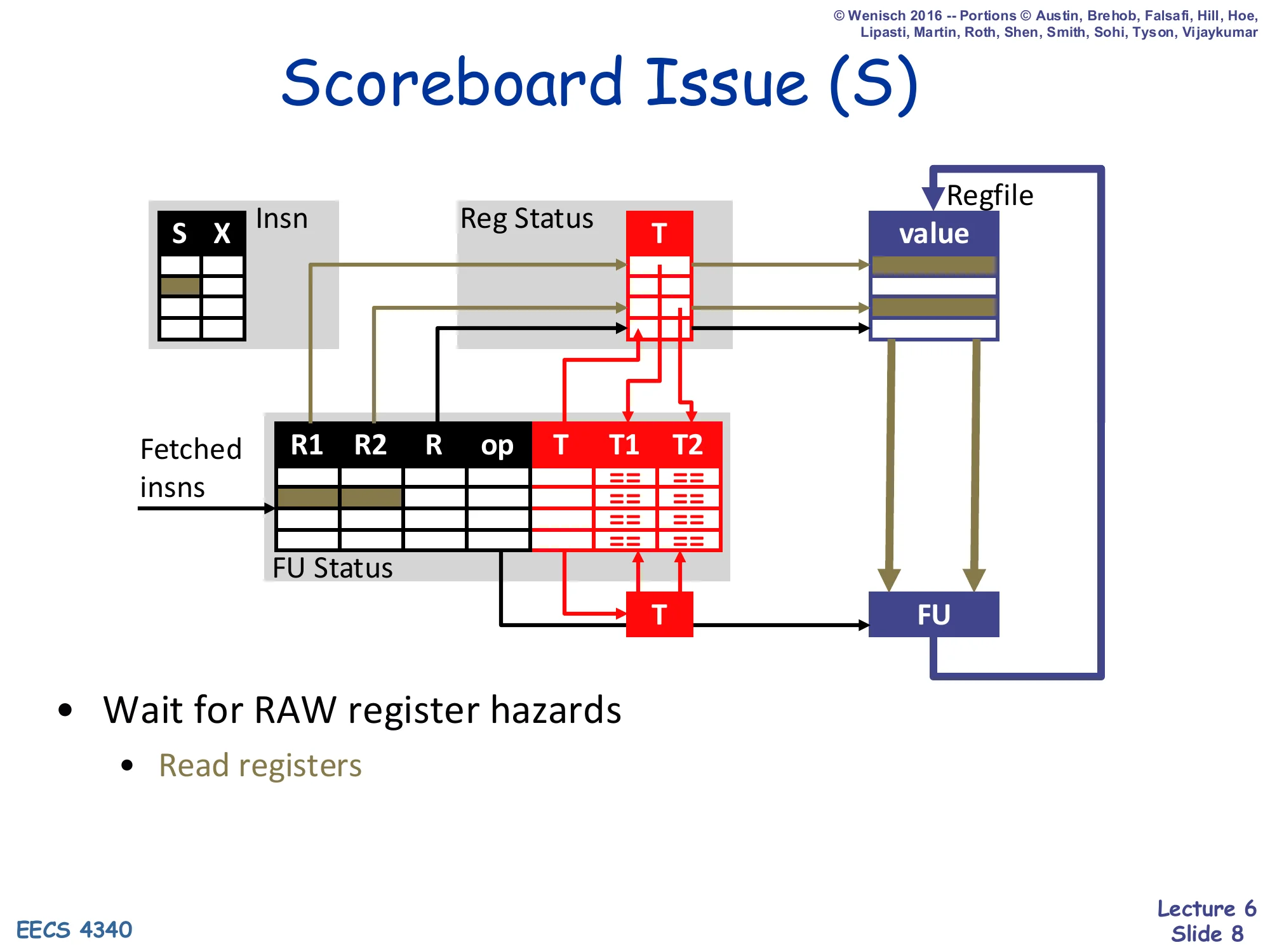
Show slide text
Scoreboard Issue (S)
- Wait for RAW register hazards
- Read registers
Issue is the out-of-order stage. Each FU watches its own T1/T2 tag fields; when both have been cleared (meaning the producers have written back), the FU asserts that this instruction is ready, reads the actual operand values from the regfile, and sends them to execute. Multiple FUs may issue out of program order in the same cycle — that’s the whole point of dynamic scheduling. Note what is not happening here: there is no value broadcast or operand snarfing — the FU just waits for the tags to clear and then reads the regfile fresh. This means the regfile must hold the producer’s value the cycle issue runs, which couples writeback and issue tightly and is also why a later writer cannot clobber the regfile until all earlier readers have issued. Hence the WAR hazard that ultimately bottlenecks the scoreboard pipeline.
Scoreboard Execute (X)
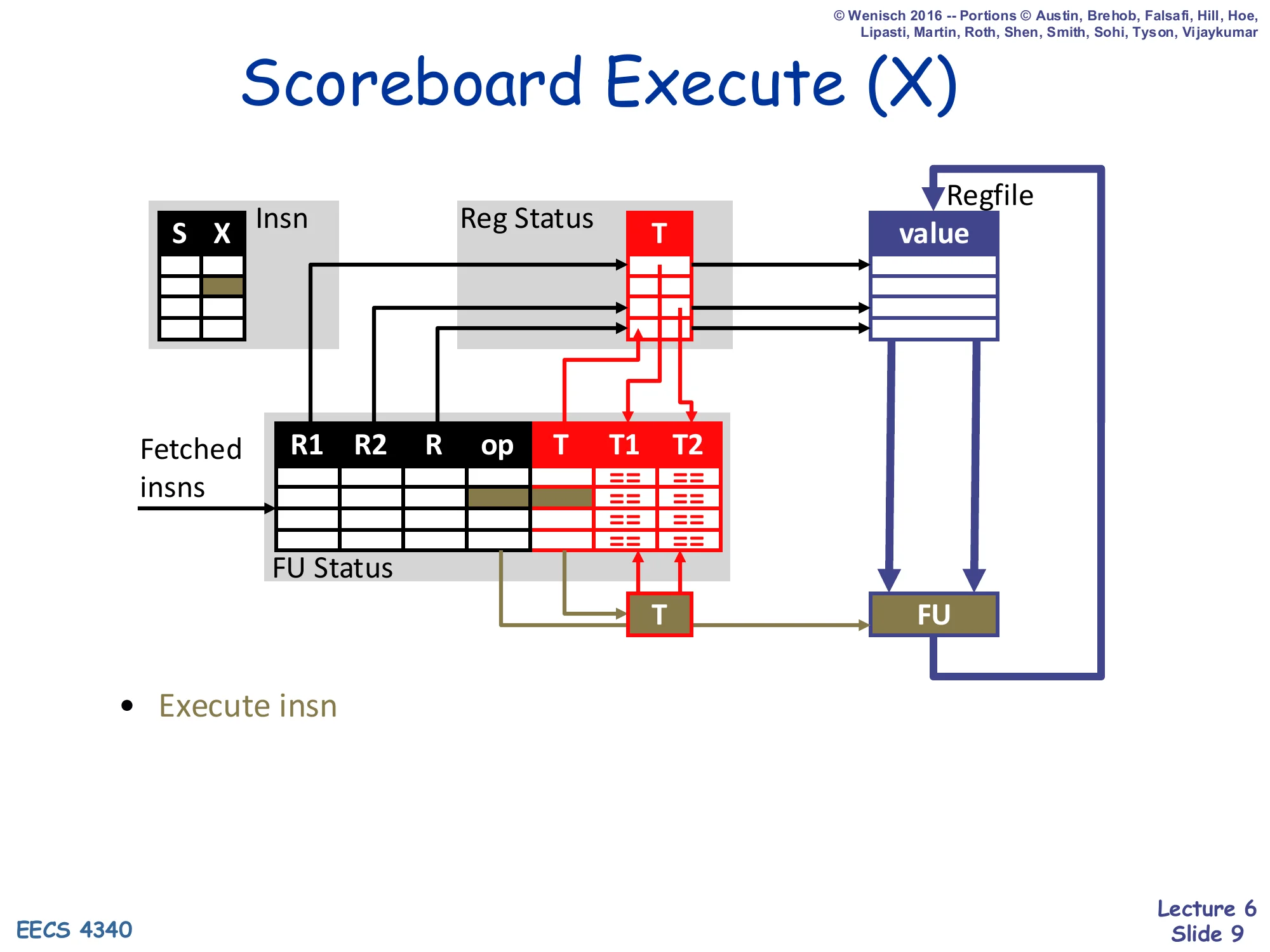
Show slide text
Scoreboard Execute (X)
- Execute insn
Execute is mostly the same as in an in-order pipeline: the FU performs the operation on the operand values it just read in S. Multi-cycle units (multiplier, divider, FP) live here and may be pipelined or iterative; either way the scoreboard tracks completion via the X status bit. When execution finishes the FU notifies the scoreboard so that writeback can be scheduled. Because there is no operand forwarding in our scoreboard, the result does not become visible to dependents until the W stage actually writes the regfile and the dependents re-issue from S — this is the “no bypassing” downside that motivates Tomasulo later in the lecture.
Scoreboard Writeback (W)
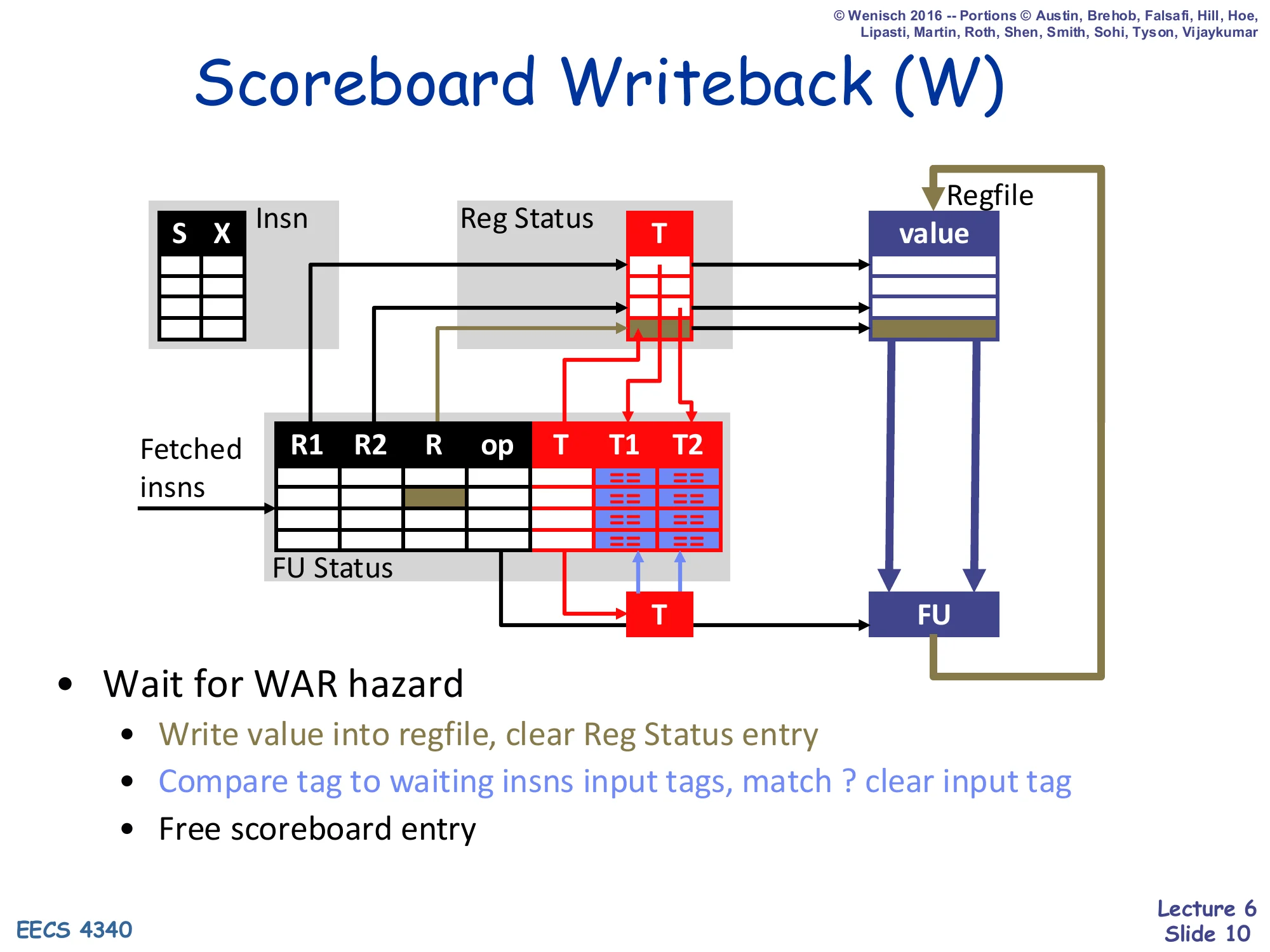
Show slide text
Scoreboard Writeback (W)
- Wait for WAR hazard
- Write value into regfile, clear Reg Status entry
- Compare tag to waiting insns input tags, match ? clear input tag
- Free scoreboard entry
Writeback is where the scoreboard pays for the absence of operand copies. The FU first checks for outstanding WAR hazards — any earlier instruction that has not yet read the destination register from the regfile blocks this writeback, because committing now would clobber a value an in-flight reader still needs. Once safe, three things happen atomically: the regfile is written with the result, the destination’s Reg Status entry is cleared (making the architectural register “available” again), and a tag broadcast walks the FU Status CAMs clearing every T1/T2 that matches this FU’s destination tag. That CAM clear is what wakes up dependent issues in the next cycle. Finally the scoreboard slot is freed for another dispatch. Memorize this: WAR delays writeback in scoreboarding (vs. WAW delaying dispatch).
In-Order vs. Scoreboard
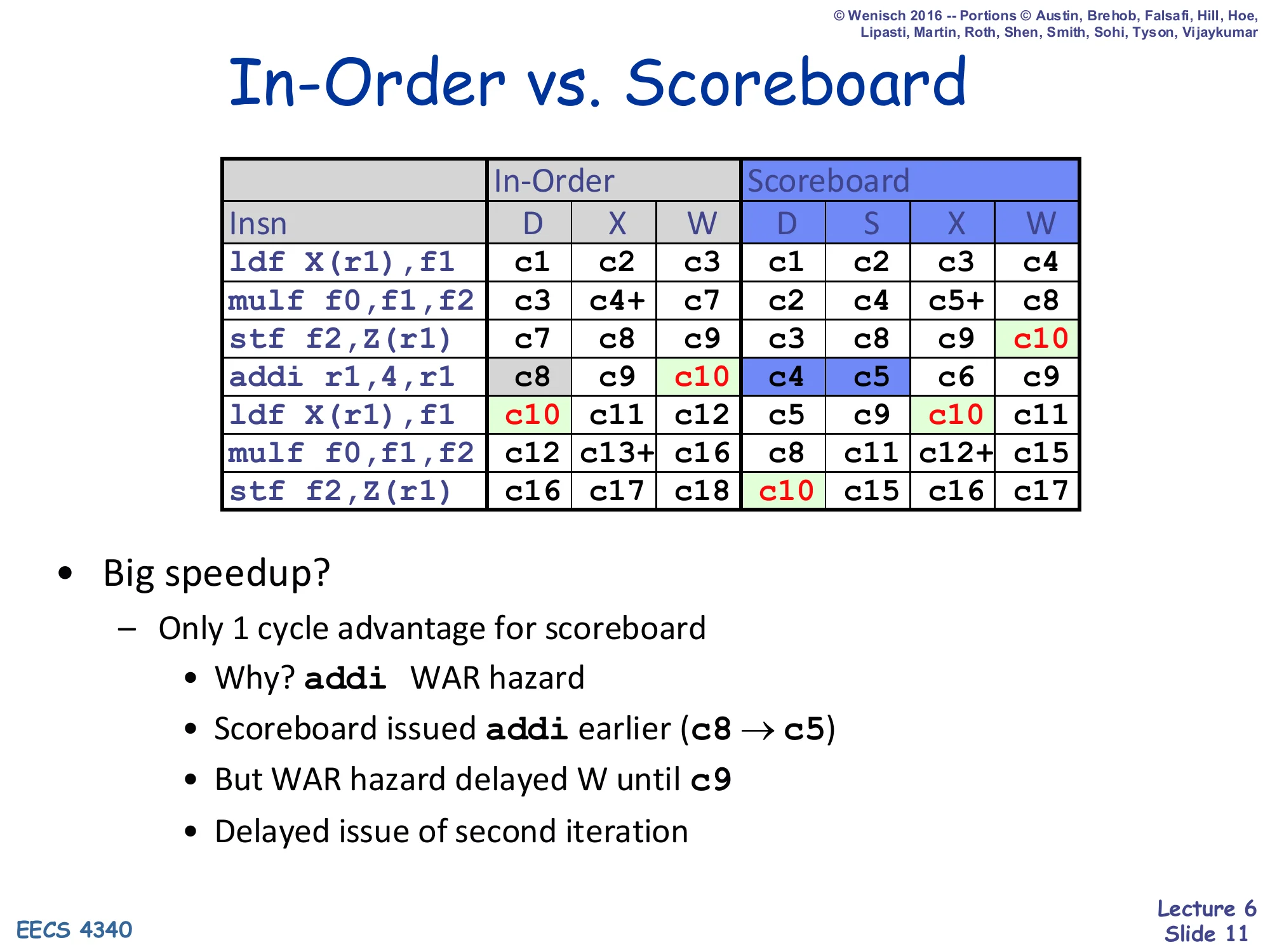
Show slide text
In-Order vs. Scoreboard
| Insn | In-Order D | X | W | Scoreboard D | S | X | W |
|---|---|---|---|---|---|---|---|
ldf X(r1),f1 | c1 | c2 | c3 | c1 | c2 | c3 | c4 |
mulf f0,f1,f2 | c3 | c4+ | c7 | c2 | c4 | c5+ | c8 |
stf f2,Z(r1) | c7 | c8 | c9 | c3 | c8 | c9 | c10 |
addi r1,4,r1 | c8 | c9 | c10 | c4 | c5 | c6 | c9 |
ldf X(r1),f1 | c10 | c11 | c12 | c5 | c9 | c10 | c11 |
mulf f0,f1,f2 | c12 | c13+ | c16 | c8 | c11 | c12+ | c15 |
stf f2,Z(r1) | c16 | c17 | c18 | c10 | c15 | c16 | c17 |
- Big speedup?
- Only 1 cycle advantage for scoreboard
- Why?
addiWAR hazard - Scoreboard issued
addiearlier (c8 → c5) - But WAR hazard delayed W until c9
- Delayed issue of second iteration
- Why?
- Only 1 cycle advantage for scoreboard
This worked example exposes the scoreboard’s structural weakness on a tight loop kernel. The compiler’s addi r1,4,r1 is the loop-counter update; its destination r1 is read by ldf X(r1)/stf …,Z(r1)/etc. earlier in the iteration, creating a WAR anti-dependence. The scoreboard happily issues addi early (cycle c5 instead of c8) because the source r1 is ready, but then the W stage blocks at c9 until every earlier reader has issued. That delay propagates: the second iteration’s ldf X(r1) cannot dispatch until addi writes back (because of the resulting WAW on r1 — actually here it is RAW on r1). Net effect: the entire second iteration starts only one cycle earlier than the in-order schedule. The diagnosis points directly at the fix on the next slide — eliminate WAR/WAW with hardware register renaming so writebacks never have to wait for old readers.
Scoreboard Redux

Show slide text
Scoreboard Redux
- The good
-
- Cheap hardware
- InsnStatus + FuStatus + RegStatus ~ 1 FP unit in area
-
- Pretty good performance
- 1.7× for FORTRAN (scientific array) programs
-
- The less good
- – No bypassing
- Is this a fundamental problem?
- – Limited scheduling scope
- Structural / WAW hazards delay dispatch
- – Slow issue of truly-dependent (RAW) insns
- WAR hazards delay writeback
- – No bypassing
- Fix with hardware register renaming
Scoreboarding is a remarkable engineering accomplishment — for roughly the area of one FP unit (1960s technology), it delivered a 1.7× speedup on the FORTRAN scientific workload that motivated the CDC 6600. But three weaknesses limit it. First, no bypassing: results have to round-trip through the regfile before dependents can read them. Second, structural and WAW hazards block dispatch — the front end can’t even consider younger independent instructions while one of these is pending. Third, WAR hazards delay writeback (and therefore the consumer of the result). The unifying observation is that WAR and WAW are false dependences caused by reusing architectural register names; replace those names with internal tags (one per in-flight write) and they vanish. The next sub-section introduces hardware register renaming, which becomes the central idea of Tomasulo’s algorithm.
Tomasulo's Algorithm

Register Renaming

Show slide text
Register Renaming
- Register renaming (in hardware)
- Change register names to eliminate WAR/WAW hazards
- One of the most beautiful things in computer architecture
- Key: think of registers (
r1,f0…) as names, not storage locations -
- Can have more locations than names
-
- Can have multiple active versions of same name
- How does it work?
- Map-table: maps names to most recent locations
- SRAM indexed by name
- On a write: allocate new location, note in map-table
- On a read: find location of most recent write via map-table lookup
- Small detail: must de-allocate locations at some point
- Map-table: maps names to most recent locations
Register renaming is the conceptual breakthrough that makes deep out-of-order execution work. The slide draws a sharp distinction: the register file you program against (r1, f0, …) is a namespace, not a fixed set of physical storage cells. Once you decouple names from locations, you can have arbitrarily many physical locations holding different historical versions of the same architectural name, and you can let multiple in-flight instructions all “write r1” without conflict — each gets its own location. The WAR and WAW hazards disappear because those hazards are artifacts of name reuse, not real data dependences. Mechanism: a map-table, an SRAM indexed by architectural name whose payload is the location of the most recent write. On every write, allocate a fresh location and update the map-table; on every read, look up the producer through the map-table. The reclamation rule (“de-allocate at some point”) is non-trivial — Tomasulo punts on it; the ROB-based renamers in L07 will reclaim on commit.
Scheduling Algorithm II: Tomasulo

Show slide text
And Now… Scheduling Algorithm II: Tomasulo
- Tomasulo’s algorithm
- Reservation stations (RS): instruction buffer
- Common data bus (CDB): broadcasts results to RS
- Register renaming: removes WAR/WAW hazards
- First implementation: IBM 360/91 [1967]
- Dynamic scheduling for FP units only
- Bypassing
- Our example: “Simple Tomasulo”
- Dynamic scheduling for everything, including load/store
- No bypassing (for comparison with Scoreboard)
- 5 RS: 1 ALU, 1 load, 1 store, 2 FP (3-cycle, pipelined)
Tomasulo’s algorithm (Robert Tomasulo, IBM 360/91, 1967) introduces three coupled mechanisms: reservation stations that buffer waiting instructions next to each FU, a common data bus that broadcasts each FU’s result tagged with its RS number, and register renaming via the map-table that points each architectural register at the RS currently producing it. Together these eliminate WAR and WAW hazards and let arbitrary instructions execute as soon as their operands are ready. The historical 360/91 only renamed FP because that was the bottleneck on scientific code; the slide announces the simplification used throughout this lecture: Simple Tomasulo renames everything (loads, stores, ALU) but disables bypassing so the comparison with scoreboarding is apples-to-apples. The 5-RS, 3-cycle-pipelined-FP configuration is what the worked example on slides 26–36 will simulate.
Tomasulo Data Structures

Show slide text
Tomasulo Data Structures
- Reservation Stations (RS#)
- FU, busy, op, R: destination register name
- T: destination register tag (RS# of this RS)
- T1, T2: source register tags (RS# of RS that will produce value)
- V1, V2: source register values
- That’s new
- Map Table
- T: tag (RS#) that will write this register
- Common Data Bus (CDB)
- Broadcasts ⟨RS#, value⟩ of completed insns
- Tags interpreted as ready-bits++
- T==0⇒ Value is ready somewhere
- T=0⇒ Value is not ready, wait until CDB broadcasts T
Each reservation station is identified by its RS# — that number doubles as the renaming tag T. The fields FU/busy/op/R are bookkeeping (which functional unit, in-use bit, opcode, destination architectural name). The new fields are the source slots: T1/T2 record the producing RS# for an unready operand, while V1/V2 hold the actual operand value once it becomes ready. This is the value-copy renaming that distinguishes Tomasulo from scoreboarding. The Map Table is one entry per architectural register, mapping name → producing RS# (tag); a tag of 0 (empty) means the regfile already holds the most-recent value. The CDB is a single shared write-back wire that broadcasts ⟨RS#, value⟩ when any FU finishes; every RS compares the broadcast RS# against its T1 and T2, and on a match latches the value into V1/V2 and clears the tag. This snarfing replaces the regfile read of scoreboarding’s S stage.
Simple Tomasulo Data Structures
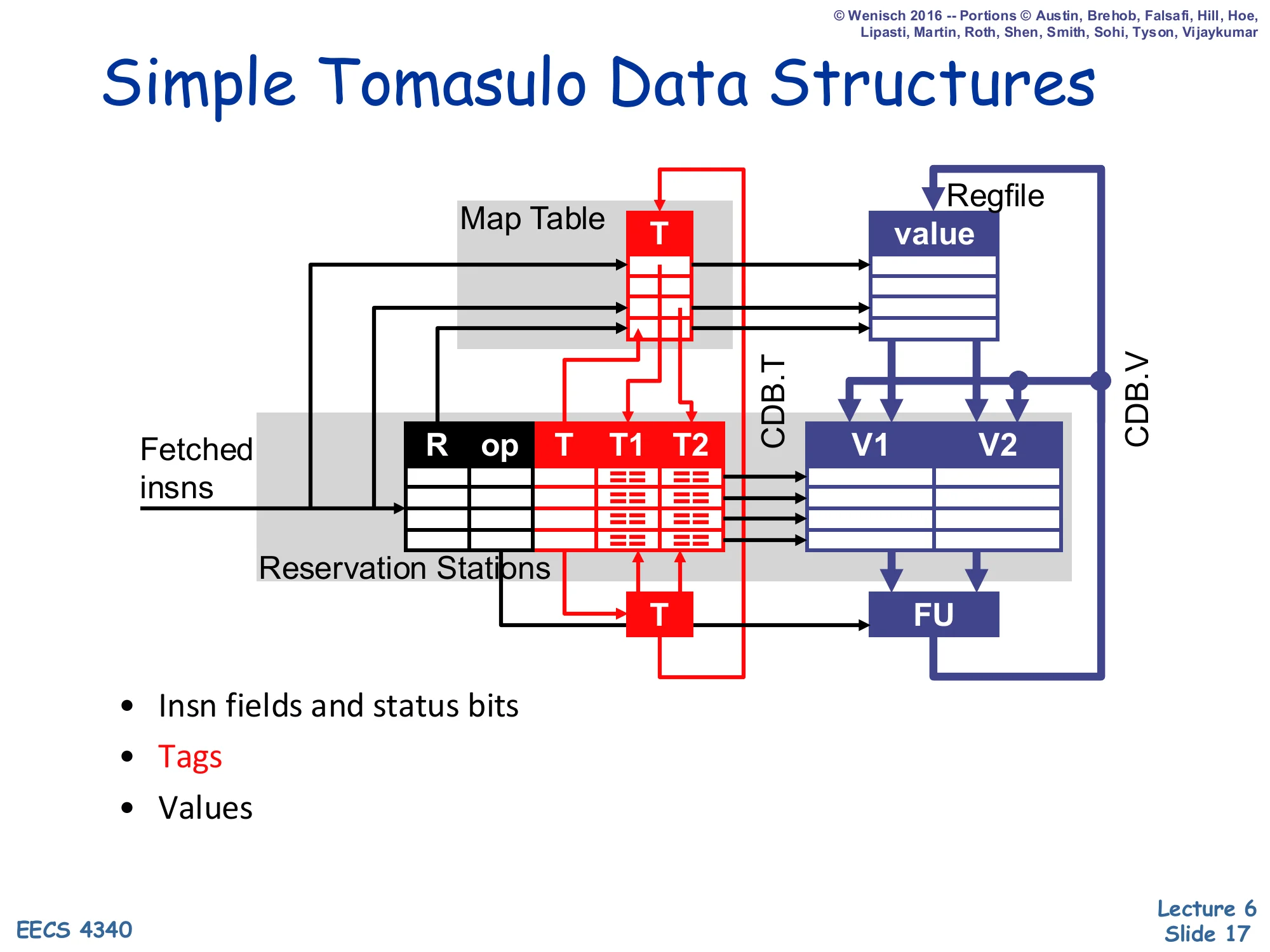
Show slide text
Simple Tomasulo Data Structures
Diagram: Map Table (T) maps each architectural register to a producing RS#, Reservation Stations hold ⟨R, op, T, T1, T2, V1, V2⟩, and the Regfile holds the master value column. CDB.T and CDB.V are the broadcast tag/value wires that snake back into the Map Table, the regfile, and every RS.
- Insn fields and status bits
- Tags
- Values
Compared to the scoreboard datapath on slide 5 the structural differences are: (1) the FU Status table is replaced by a bank of reservation stations that own their own copies of the operands (V1/V2), (2) Reg Status is renamed Map Table but plays the same role of architectural-name → producing-tag indirection, and (3) there is now an explicit CDB wire that fans out from every FU back to the Map Table, the regfile, and every RS source field. The CDB is what makes register renaming actually work end-to-end: when RS# k completes, every consumer waiting on tag k snarfs the value off the bus in the same cycle, regardless of whether that consumer is a downstream RS, the regfile, or the Map Table itself. The black cells under FU Status disappear because operands no longer need to be re-read from the regfile at issue — they were captured at dispatch (or via CDB).
Simple Tomasulo Pipeline

Show slide text
Simple Tomasulo Pipeline
New pipeline structure: F, D, S, X, W
- D (dispatch)
- Structural hazard ? stall : allocate RS entry
- S (issue)
- RAW hazard ? wait (monitor CDB) : go to execute
- W (writeback)
- Write register, free RS entry
- W and RAW-dependent S in same cycle
- W and structural-dependent D in same cycle
Compare this pipeline to scoreboarding on slide 6 — it is shorter, not longer. Dispatch stalls only for structural hazards (no free RS); WAW no longer stalls because renaming gives the new writer its own tag, and the older same-name writer’s tag simply ages out of the Map Table. Issue still waits for RAW resolution but does so by monitoring the CDB rather than the regfile — when CDB.T matches a still-pending T1/T2, the RS snarfs CDB.V and the operand is ready. Writeback has no WAR check at all because all earlier readers captured value copies into their RS at dispatch (or off the CDB); the regfile can be overwritten safely. The two same-cycle bypass rules are inherited from scoreboarding so a writeback can unblock a back-to-back issue or a back-to-back dispatch in the same cycle without a one-cycle bubble.
Tomasulo Dispatch (D)
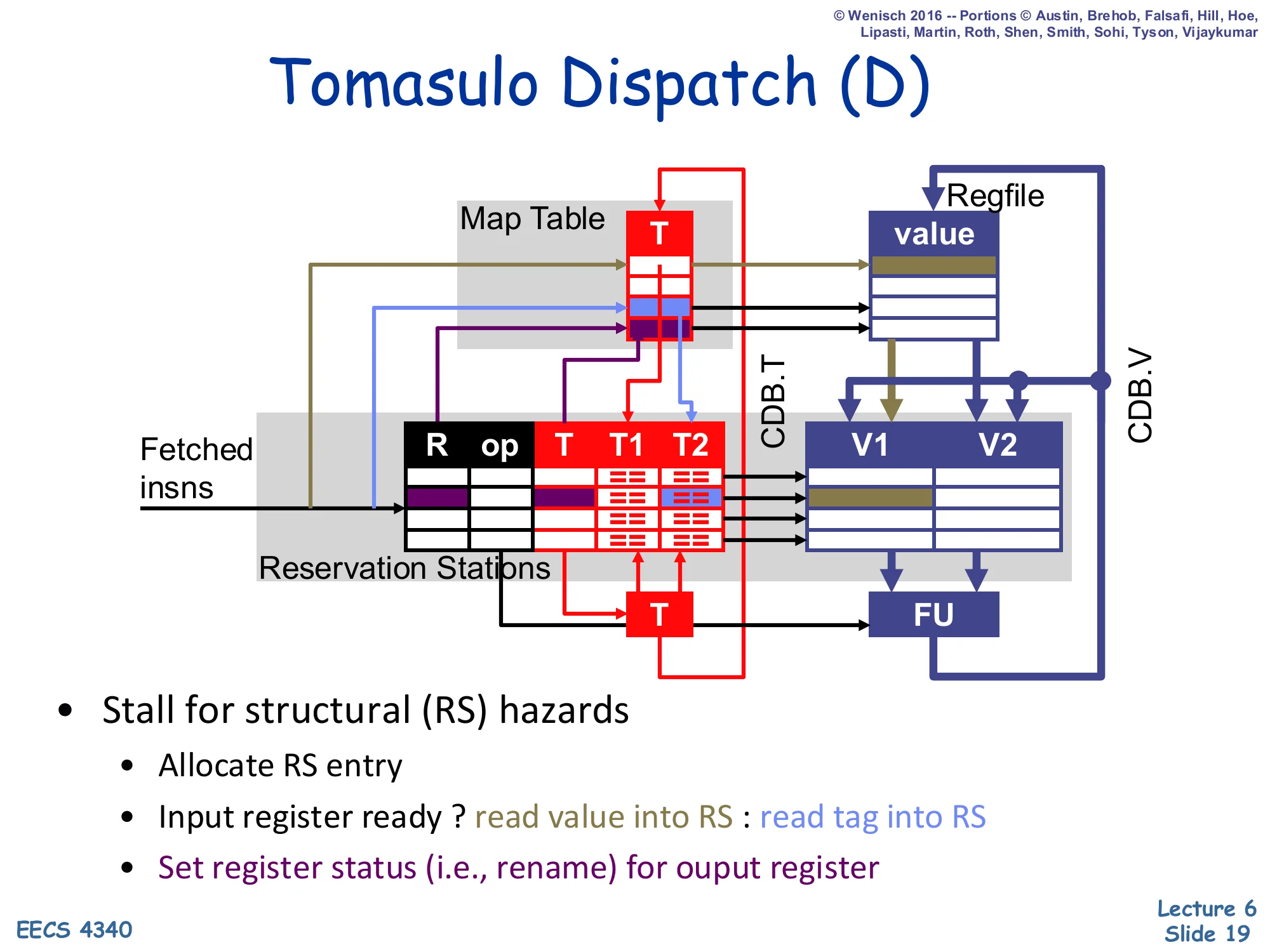
Show slide text
Tomasulo Dispatch (D)
- Stall for structural (RS) hazards
- Allocate RS entry
- Input register ready ? read value into RS : read tag into RS
- Set register status (i.e., rename) for output register
Dispatch is where renaming actually happens. For each source operand, the RS consults the Map Table: if the tag T is 0 the architectural register already holds the most recent value, so the RS reads the value from the regfile straight into V1 (or V2) and marks T1=0 (ready). Otherwise the producer is still in flight, so the RS reads the producer’s tag into T1/T2 and leaves the value slot empty until the CDB delivers it. For the destination, dispatch writes this RS’s number into the Map Table entry for R, renaming R to point at this fresh location — any later reader will pick up this RS as the producer instead of an older value. There is no WAW stall: an older still-pending writer’s tag just stops being visible to future readers, but it lives on inside whichever RS already captured it. The only stall reason is a structural hazard — no free RS — which the next slide on cycle 6 will demonstrate is rare in practice.
Tomasulo Issue (S)
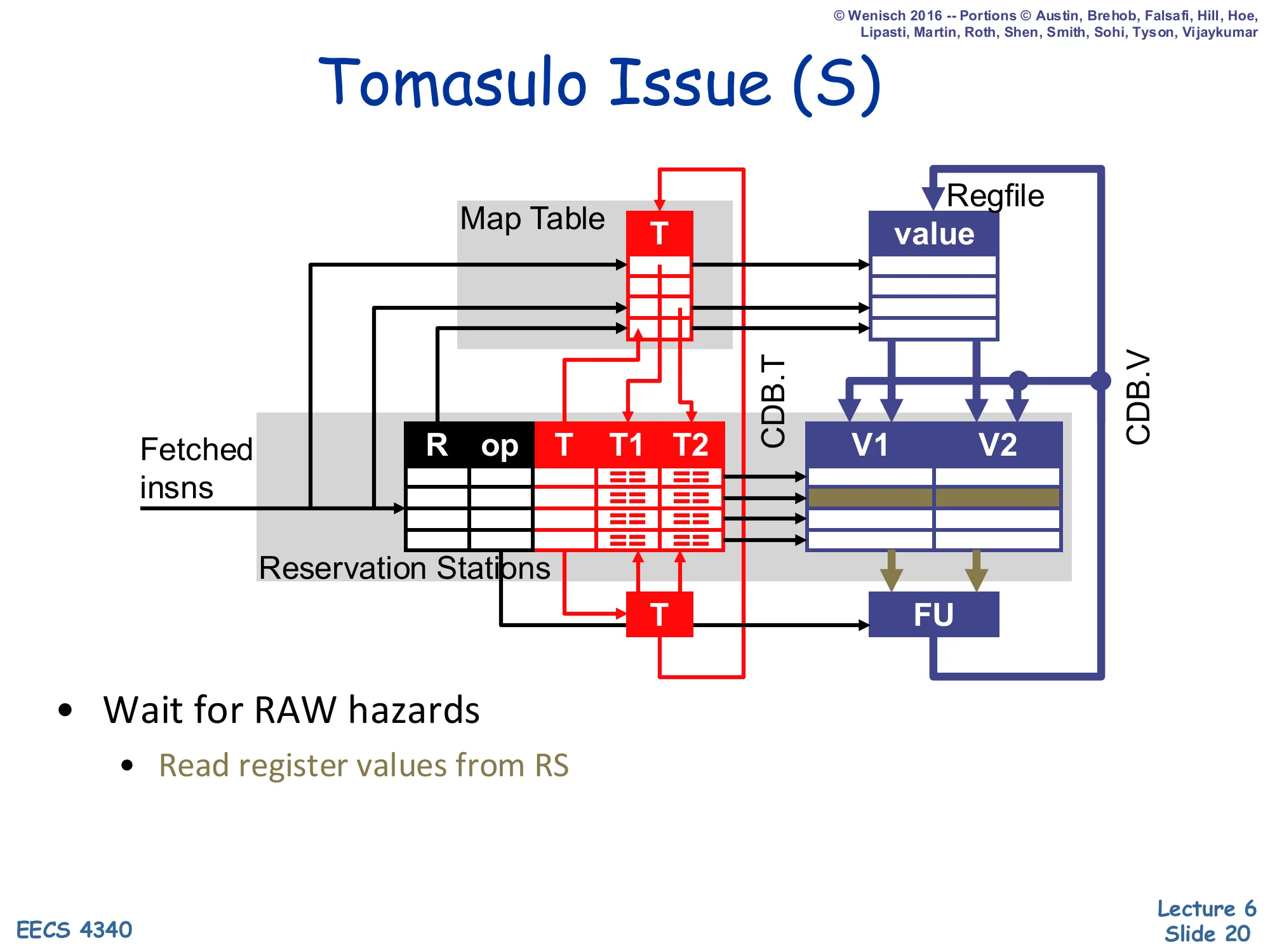
Show slide text
Tomasulo Issue (S)
- Wait for RAW hazards
- Read register values from RS
Issue in Tomasulo is even simpler than in scoreboarding. Each RS continuously OR-reduces “T1==0 AND T2==0” — i.e., both source value slots have been filled — and asserts a ready signal. Select logic picks one ready RS per FU per cycle and forwards its V1/V2 directly to the FU. Crucially, the regfile is not read at issue, because by construction whatever the RS holds in V1/V2 is already the renamed, correct value (either captured at dispatch or delivered by the CDB). This decoupling is what allows multiple in-flight instructions writing the same architectural name to coexist: each holds an independent value-copy and ages out independently. The cost is that every RS needs CAM-style tag comparators on the CDB, which is the limit on Tomasulo scalability discussed on slide 39.
Tomasulo Execute (X)
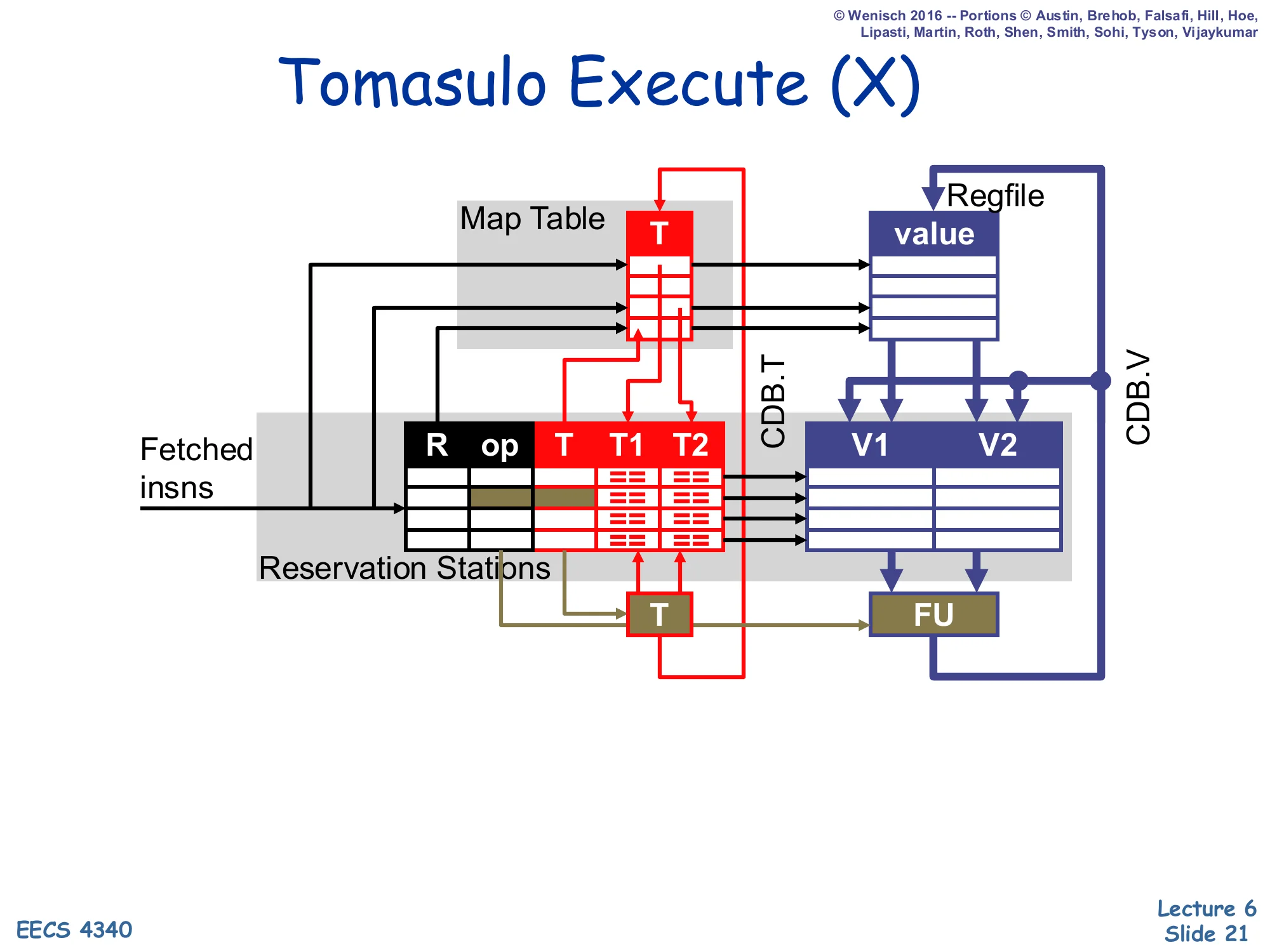
Show slide text
Tomasulo Execute (X)
(Execute the instruction in the functional unit; multi-cycle FUs notify the scheduler when done.)
Execute is essentially identical to scoreboarding’s X stage: the FU consumes V1/V2 supplied by the issued RS and produces a result after one or more cycles. The Simple Tomasulo configuration uses 3-cycle pipelined FP units, so the c5+ entries in the worked example mean “started in c5, finishes in c7.” Loads also live here — note the slight extension that the load FU computes its address from V1 (the base) plus an immediate, then accesses the cache. Stores (handled by the ST RS) wait at execute until both their address-base value and their data value are present, then write the cache. When execute finishes the FU arbitrates for the CDB and proceeds to writeback.
Tomasulo Writeback (W)
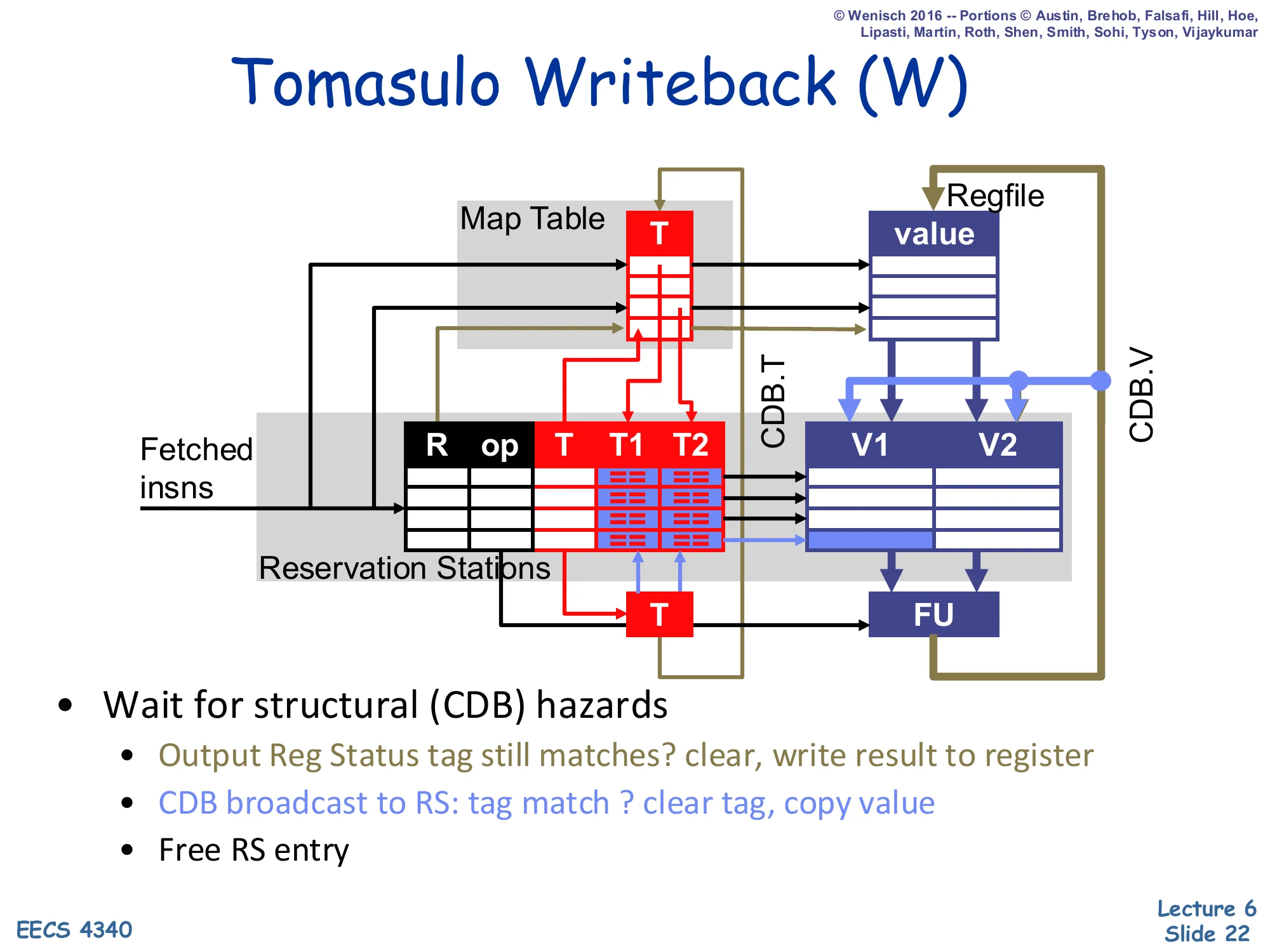
Show slide text
Tomasulo Writeback (W)
- Wait for structural (CDB) hazards
- Output Reg Status tag still matches? clear, write result to register
- CDB broadcast to RS: tag match ? clear tag, copy value
- Free RS entry
Writeback in Tomasulo is the place where the CDB earns its keep. The only stall reason is a structural CDB conflict — two FUs finishing the same cycle compete for the single broadcast wire, so one wins and the other waits. Once a winner is selected, three parallel actions occur: (1) if the destination register’s Map Table entry still equals this RS#, clear the entry and write the value into the regfile (this is the master update — but it can be safely overwritten later because any current consumer already has a value-copy); if the Map Table has moved on to a newer producer, the regfile write is suppressed — that is a stale tag and would corrupt state (see cycle 8 on slide 34). (2) Every RS compares CDB.T against T1 and T2; on a match the tag is cleared and CDB.V is latched into V1/V2. (3) The producing RS is freed for reuse. There is no WAR check anywhere — that hazard simply does not exist in Tomasulo.
Difference Between Scoreboard…
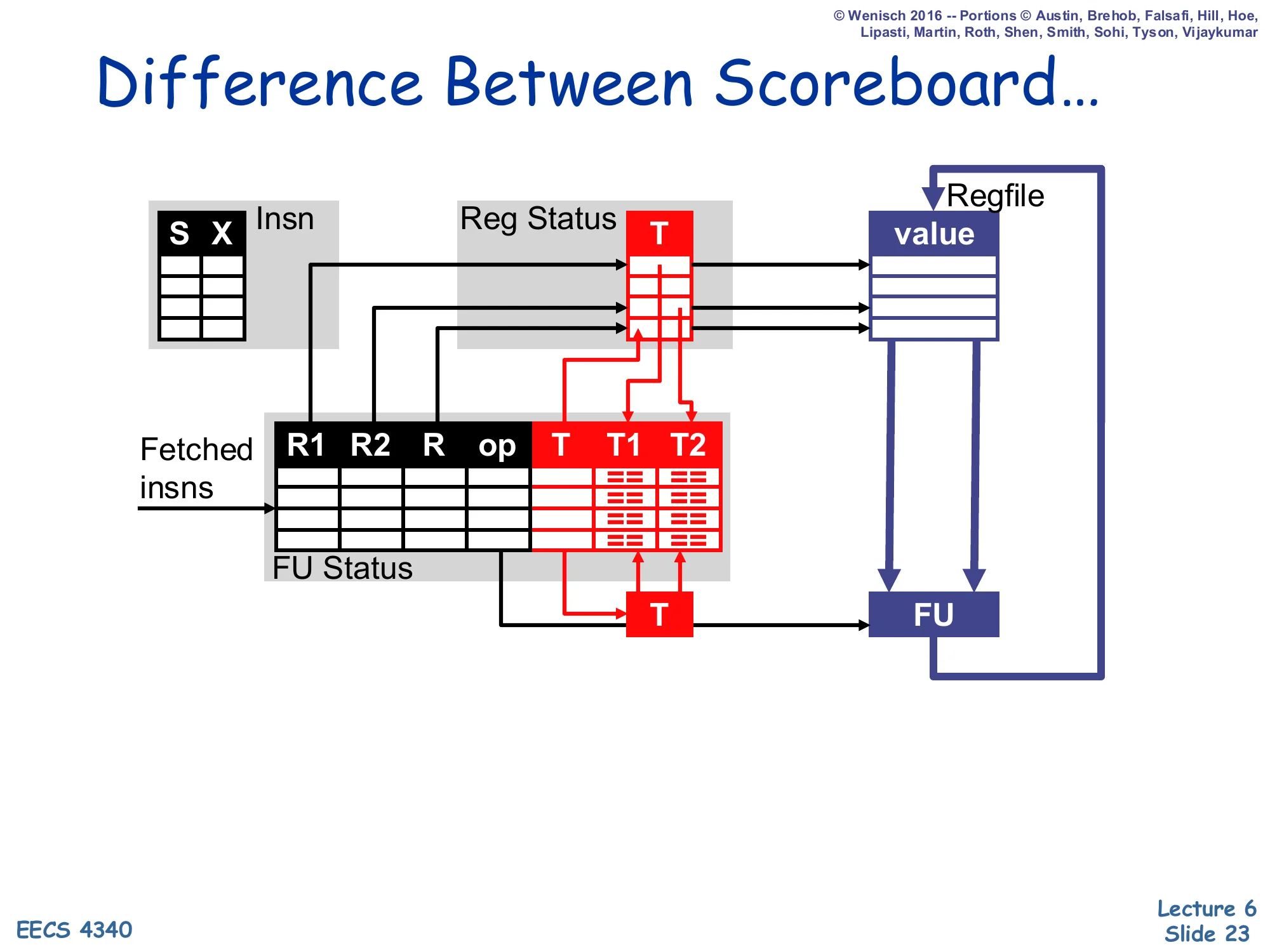
Show slide text
Difference Between Scoreboard…
Reprise of the scoreboard datapath: Insn (S, X), Reg Status (T), FU Status (R1, R2, R, op, T, T1, T2), regfile (value), FU. No V1/V2 columns inside the FU table — values live only in the regfile.
This is the visual setup for the side-by-side that follows. Compared to the diagram on the next slide, the scoreboard has only one place to keep operand values: the regfile. The FU table holds source register names R1/R2 and tags T1/T2 but never the values themselves. That is why writeback has to wait for outstanding readers — the regfile is the single shared storage, and overwriting it before a reader has issued would lose the older value. The next slide will show how Tomasulo eliminates this by adding V1/V2 to every reservation station.
…And Tomasulo
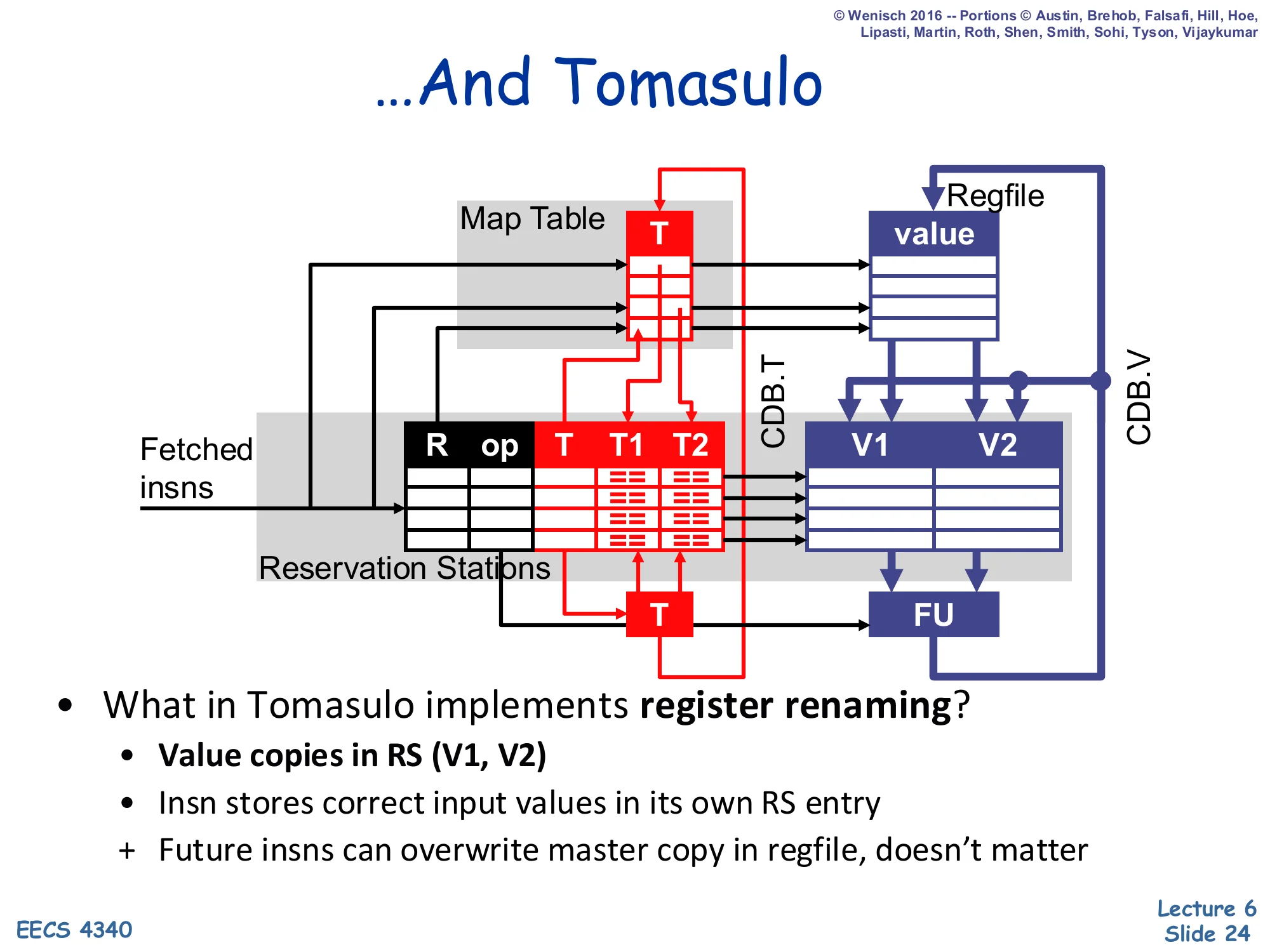
Show slide text
…And Tomasulo
- What in Tomasulo implements register renaming?
- Value copies in RS (V1, V2)
- Insn stores correct input values in its own RS entry
-
- Future insns can overwrite master copy in regfile, doesn’t matter
The single-sentence answer to “what does the renaming?” is the V1/V2 columns in the reservation station. Once an instruction has captured its input values into its own RS entry — either at dispatch (if the regfile already had them) or off the CDB (if the producer had not yet finished at dispatch time) — the regfile entry for that register is no longer load-bearing for that instruction. Any later writer can clobber the master regfile copy and even overwrite the Map Table tag without affecting in-flight readers, because the readers already have private value copies. This is precisely why the WAR and WAW hazards vanish in Tomasulo: they were artifacts of having a single shared storage location per architectural name. Spread the storage across every RS that captures a copy and the false dependences disappear. This style of renaming is called value-based or copy-based — to be contrasted with the physical-register-file style introduced in L08 (MIPS R10000).
Value/Copy-Based Register Renaming

Show slide text
Value/Copy-Based Register Renaming
- Tomasulo-style register renaming
- Called value-based or copy-based
- Names: architectural registers
- Storage locations: register file and reservation stations
- Values can and do exist in both
- Register file holds master (i.e., most recent) values
-
- RS copies eliminate WAR hazards
- Storage locations referred to internally by RS# tags
- Register table translates names to tags
- Tag == 0 value is in register file
- Tag != 0 value is not ready and is being computed by RS#
- CDB broadcasts values with tags attached
- So insns know what value they are looking at
This is the formal taxonomy for what we just built. Names are the small fixed set of architectural registers exposed by the ISA. Locations are the much larger set of internal storage cells: the master regfile plus one V1/V2 pair per RS slot. The same architectural name can simultaneously have a value in the regfile (the most recently committed write) and in one or more RS slots (older readers’ captured copies and the still-running newer producer). Internally everything is referenced by RS# tags, with a special tag value 0 reserved to mean “located in the regfile.” The Map Table is the only translator between the two namespaces, and the CDB is the only mover of values between locations. This decoupled view — which is what later renaming designs all generalize — is why slide 14 calls renaming “one of the most beautiful things in computer architecture.”
Tomasulo Data Structures (Worked Example)
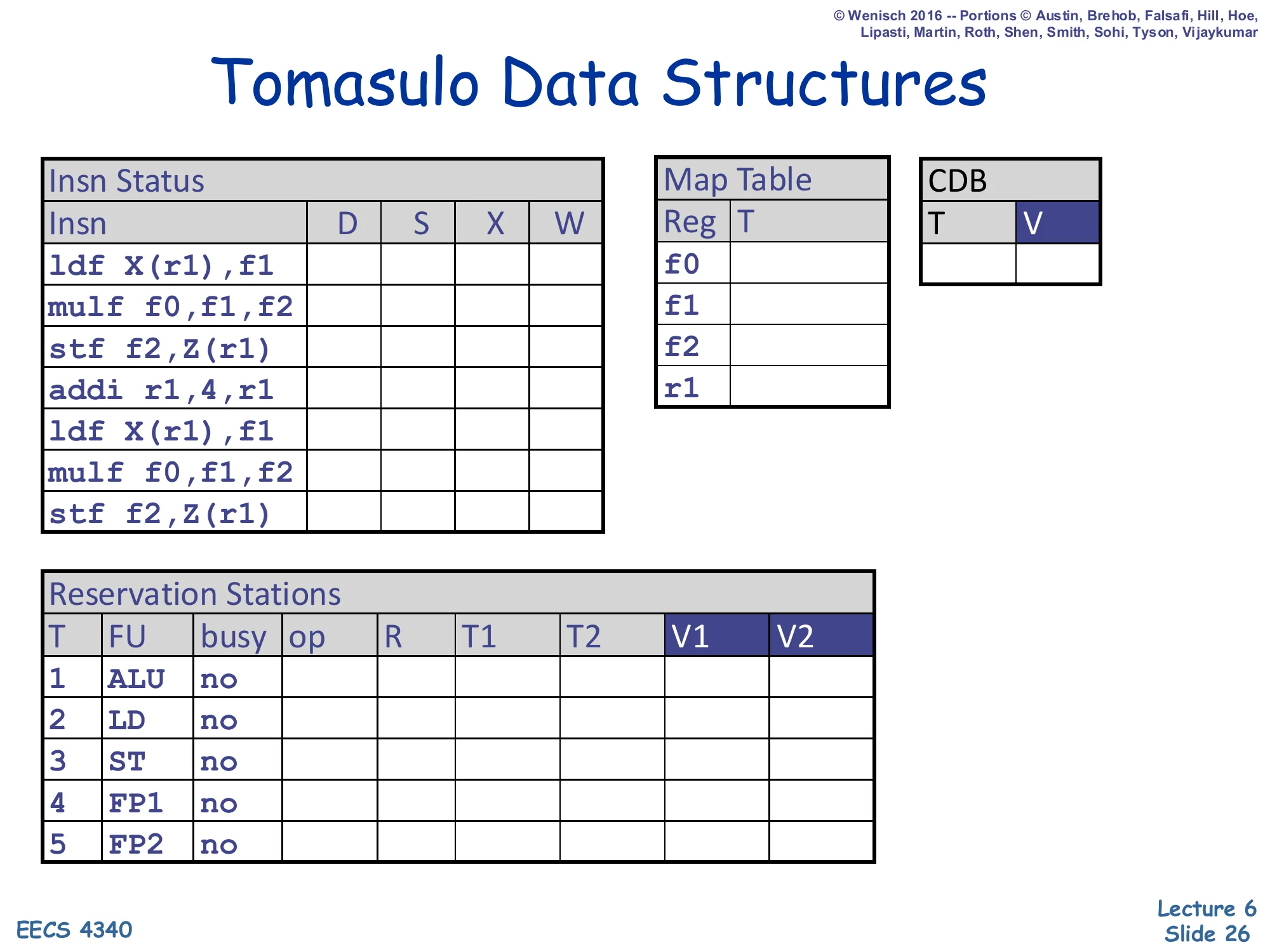
Show slide text
Tomasulo Data Structures (Worked Example)
Initial state for the trace on the next 10 slides.
- Insn Status: 7 instructions (
ldf X(r1),f1;mulf f0,f1,f2;stf f2,Z(r1);addi r1,4,r1;ldf X(r1),f1;mulf f0,f1,f2;stf f2,Z(r1)), columns D/S/X/W all empty. - Map Table: rows for
f0,f1,f2,r1— all empty. - CDB: T, V — empty.
- Reservation Stations: 5 slots with FU = ALU/LD/ST/FP1/FP2, all
busy=no.
This is the starting configuration for the cycle-by-cycle trace that occupies the next ten slides. The instruction stream is two iterations of a small loop kernel — load f1, multiply into f2, store f2, increment r1, repeat. The reservation station inventory is fixed at 5 entries (one ALU, one load, one store, two FP) — note that this is a hard cap and cycles 5–6 will demonstrate the resulting structural-hazard stall on the second mulf. The empty Map Table means every architectural register currently lives in the regfile. The empty CDB row means no FU is broadcasting a result this cycle. As you read the trace, watch how the V1/V2 columns fill up either with bracketed values like [r1] (read from regfile at dispatch) or with RS# tags (waiting for a producer).
Tomasulo: Cycle 1
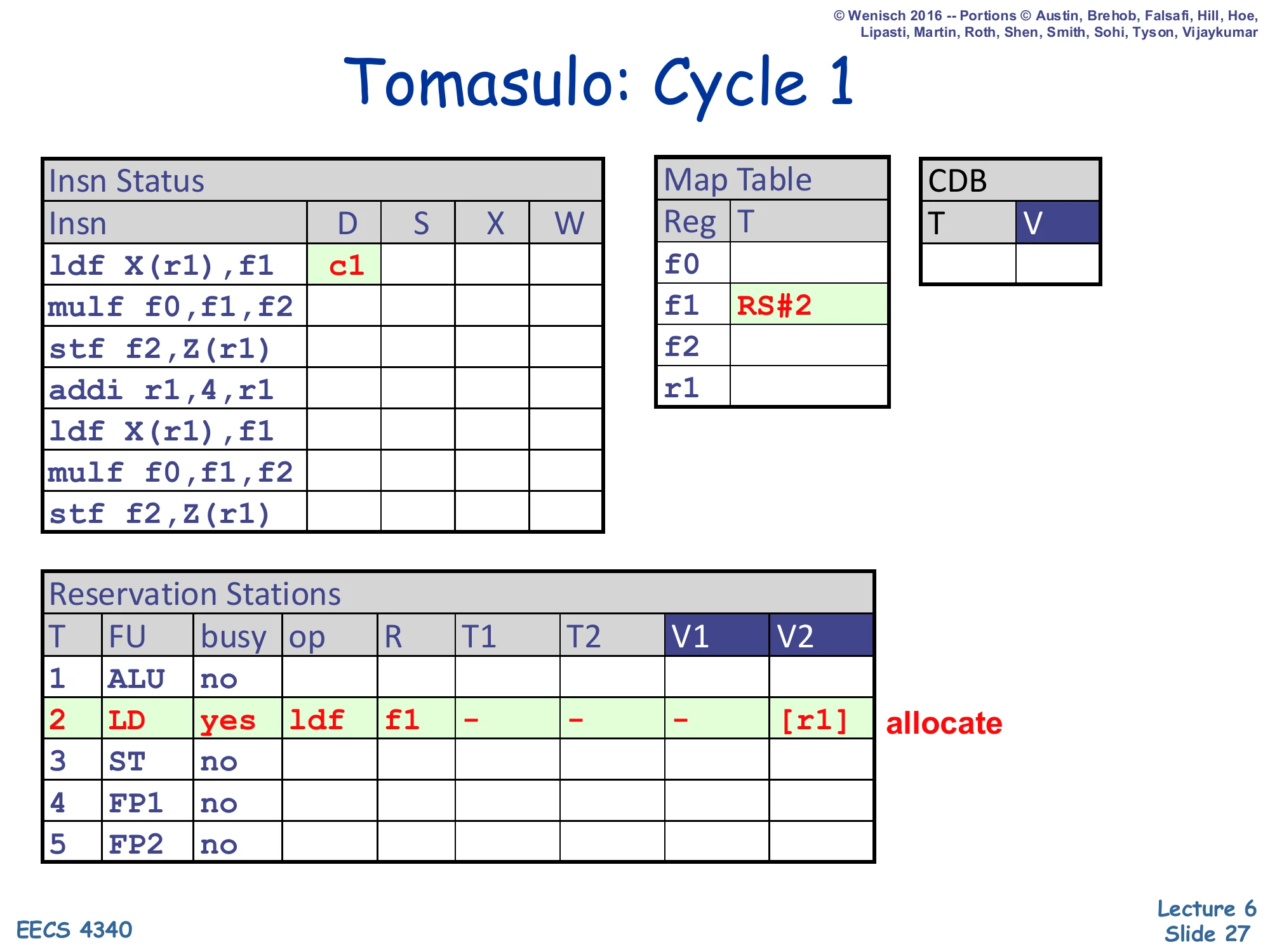
Show slide text
Tomasulo: Cycle 1
- Insn Status:
ldf X(r1),f1D=c1. - Map Table:
f1→ RS#2. - RS#2 (LD): busy=yes, op=ldf, R=f1, T1/T2/V1=–, V2=
[r1]. Allocate.
First cycle. The first ldf is dispatched into the only load reservation station, RS#2. Three things happen at once: (1) RS#2 is marked busy with op=ldf and destination architectural name R=f1. (2) Because the source operand is r1 and r1’s Map Table entry is empty (tag 0), the RS reads the value of r1 from the regfile straight into V2 — shown as [r1] to mean “the value currently sitting in r1”. V1 is unused for a one-source load, hence the dash. (3) The Map Table entry for f1 is set to RS#2, renaming f1 to point at this in-flight producer. Any later instruction that reads f1 will now see RS#2 as its tag rather than the regfile. This single dispatch event is the prototype for everything that follows.
Tomasulo: Cycle 2
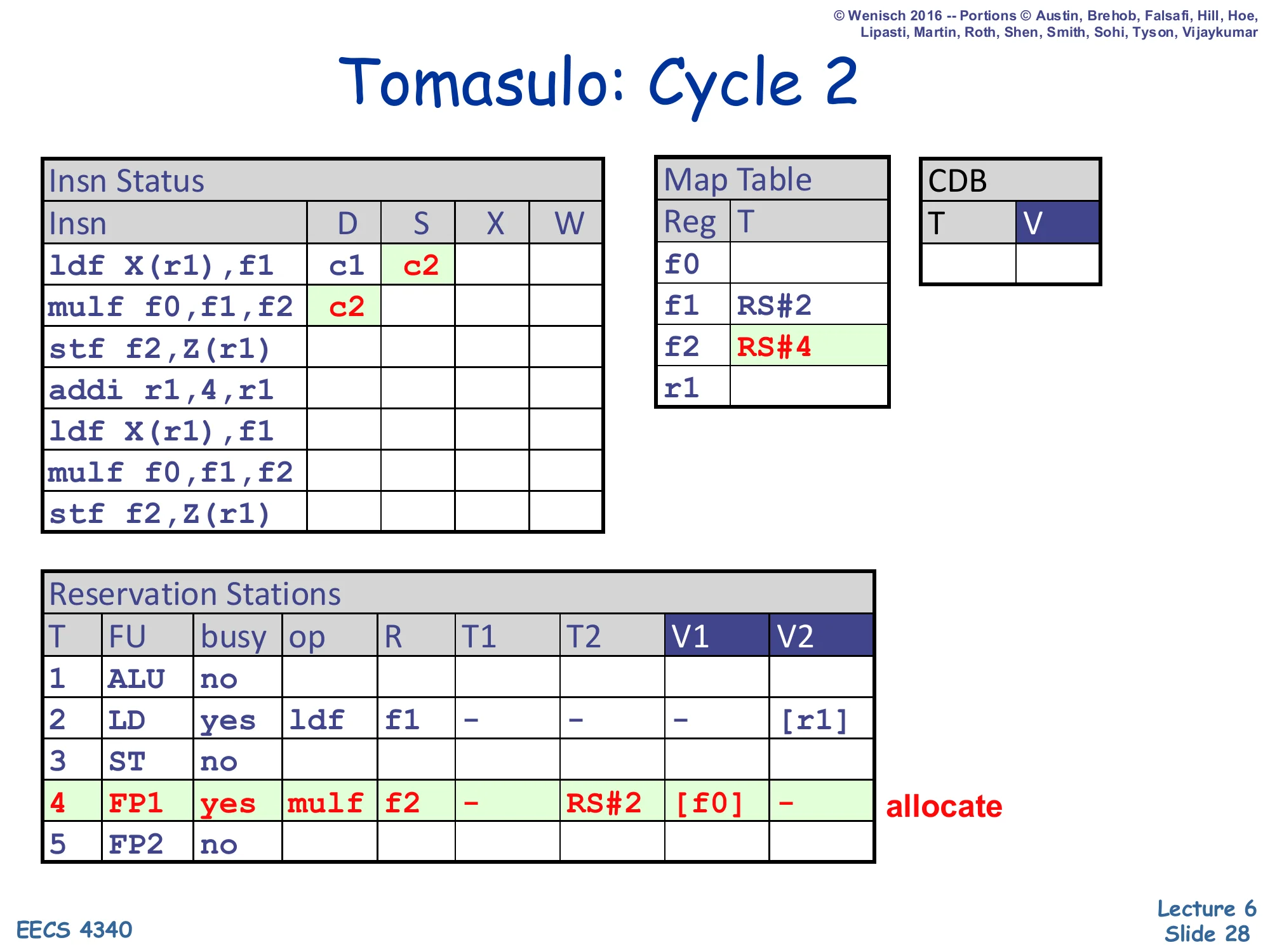
Show slide text
Tomasulo: Cycle 2
- Insn Status:
ldfS=c2;mulf f0,f1,f2D=c2. - Map Table:
f1→ RS#2 (still);f2→ RS#4. - RS#4 (FP1): busy=yes, op=mulf, R=f2, T1=–, T2=RS#2, V1=
[f0], V2=–. Allocate.
Cycle 2 simultaneously issues ldf (its operands V2=[r1] are ready, so it ships to the load FU) and dispatches the mulf f0,f1,f2. The dispatch demonstrates both halves of the renaming check: source f0 has an empty Map Table tag, so its value is read straight from the regfile into V1 (shown [f0]); source f1 has Map Table tag RS#2 (set last cycle), so the producer is in flight and the RS records T2 = RS#2 instead of a value. Destination f2 is renamed in the Map Table to RS#4. Now mulf will sit in RS#4 and watch the CDB for tag RS#2; when that broadcast arrives the V2 slot gets filled and the instruction becomes ready to issue. This is exactly the RAW resolution mechanism described on slide 18.
Tomasulo: Cycle 3
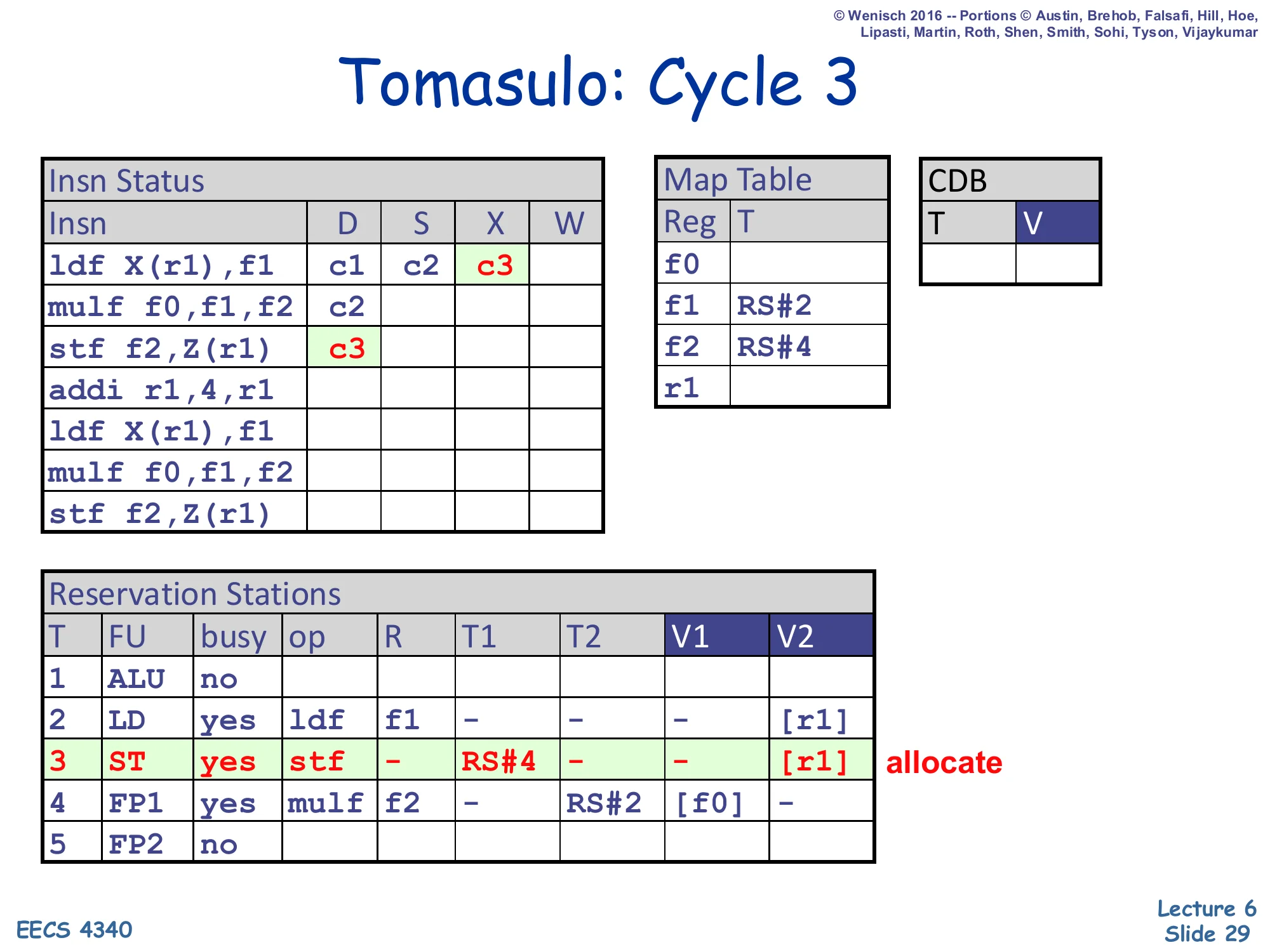
Show slide text
Tomasulo: Cycle 3
- Insn Status:
ldfX=c3;stf f2,Z(r1)D=c3. - Map Table:
f1→RS#2,f2→RS#4. - RS#3 (ST): busy=yes, op=stf, R=–, T1=RS#4, T2=–, V1=–, V2=
[r1]. Allocate.
Cycle 3 dispatches the stf f2,Z(r1). Stores have no architectural destination so R is blank and the Map Table is not updated. Source f2 has Map Table tag RS#4 (the still-pending mulf), so T1=RS#4 and V1 is empty — the store will sit in RS#3 and wait for mulf to broadcast. Source r1 has no producer (tag 0), so V2=[r1] is captured directly from the regfile. Meanwhile ldf advances to X (executing the cache access). Notice the wonderful effect of value-copy renaming: even when addi r1,4,r1 later changes r1, RS#3 already owns its own copy of the old r1 value and will compute the correct store address. This is what slide 24 means by “future insns can overwrite master copy in regfile, doesn’t matter.”
Tomasulo: Cycle 4
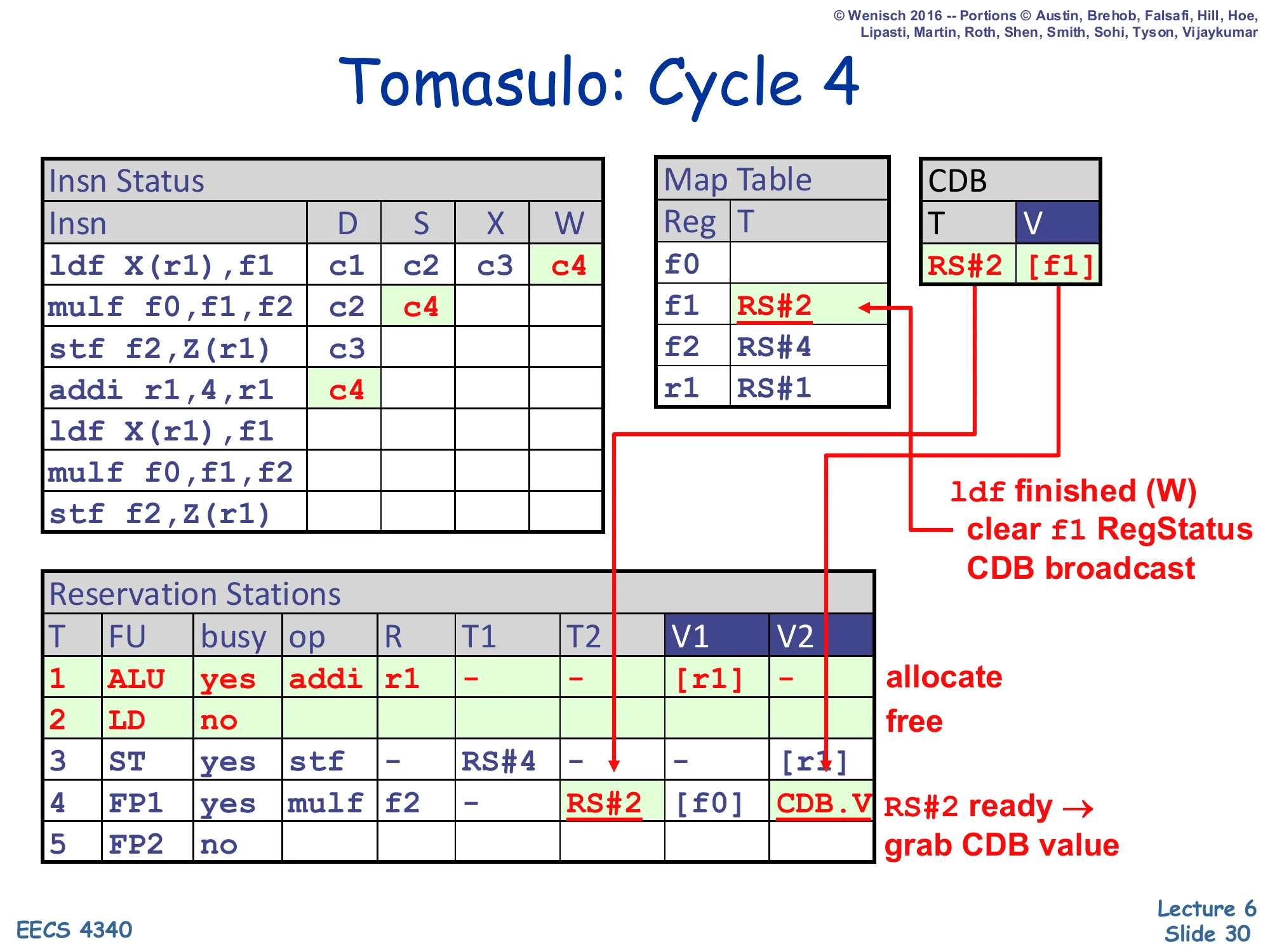
Show slide text
Tomasulo: Cycle 4
- Insn Status:
ldfW=c4;mulfS=c4;addi r1,4,r1D=c4. - CDB: T=RS#2, V=
[f1]. - Map Table:
f1→ RS#2 (cleared by W);f2→RS#4;r1→RS#1. - RS#1 (ALU): allocate (addi). RS#2 (LD): free. RS#4 (FP1): T2=RS#2 → CDB.V (grab value).
ldf finished (W) → clear f1 RegStatus, CDB broadcast. RS#2 ready → grab CDB value.
This is the lecture’s flagship cycle — every Tomasulo mechanism fires at once. The ldf finishes execute and writes back: the CDB broadcasts ⟨T=RS#2, V=[f1]⟩, the Map Table entry for f1 is cleared (because it still pointed at RS#2), and the regfile cell for f1 is updated. Simultaneously RS#4’s CAM matches T2=RS#2 against the broadcast tag, snarfs the value into V2, and clears T2 — so mulf can issue this very same cycle (S=c4). Meanwhile, on the front end, addi r1,4,r1 dispatches into RS#1: it captures [r1] into V1 from the regfile and renames r1 → RS#1 in the Map Table. Notice what does not happen: there is no WAR stall on addi even though earlier instructions still have r1-derived state in their RS entries — those RS slots own their own copies, so addi can rename freely. This is the slide that crystallizes Tomasulo’s advantage over scoreboarding.
Tomasulo: Cycle 5
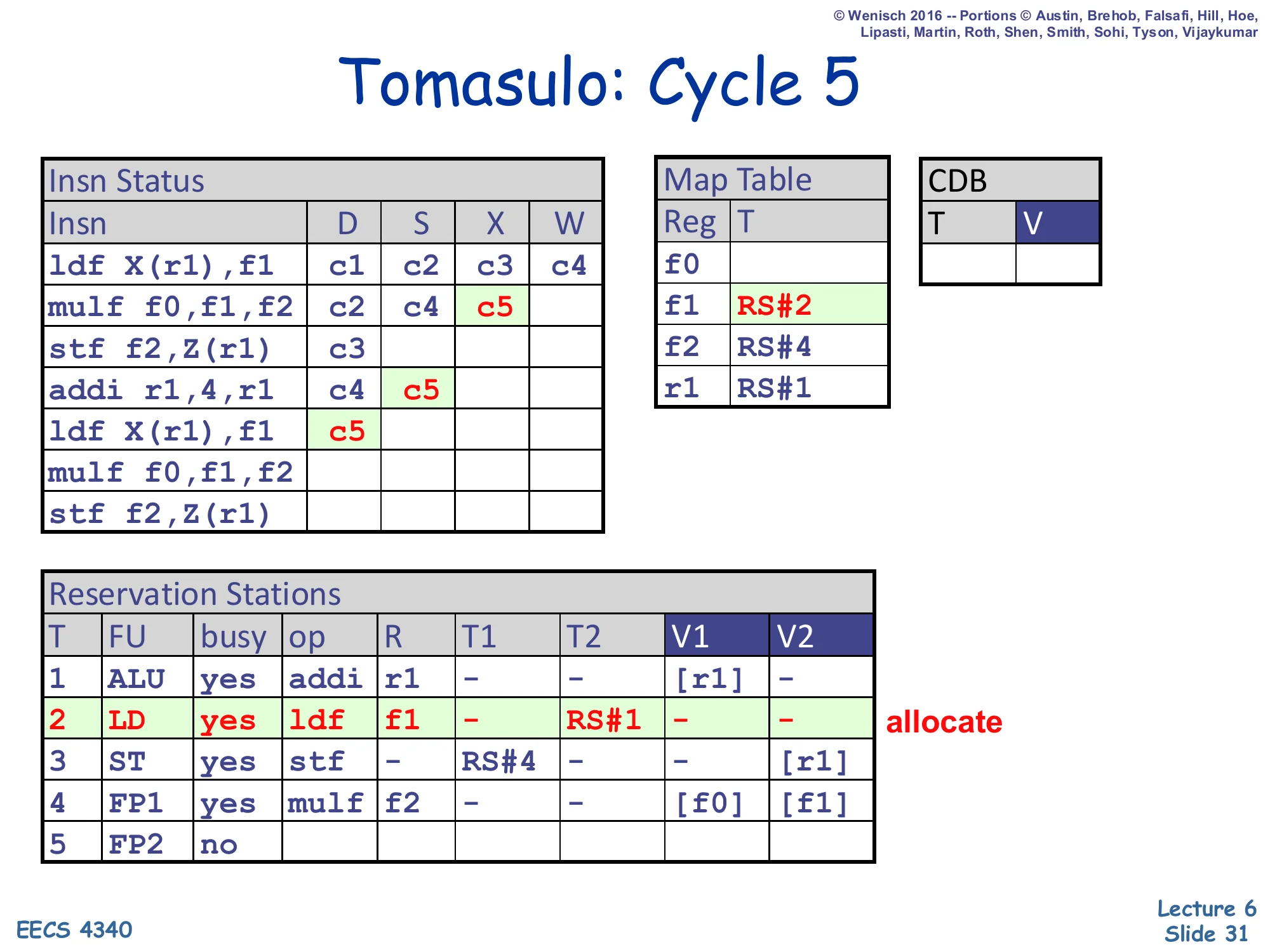
Show slide text
Tomasulo: Cycle 5
- Insn Status:
mulfX=c5;addiS=c5; secondldf X(r1),f1D=c5. - Map Table:
f1→RS#2,f2→RS#4,r1→RS#1. - RS#2 (LD): allocate again (busy=yes, op=ldf, R=f1, T2=RS#1). RS#4 (FP1): V2=
[f1]now.
RS#2 was freed at end of cycle 4 (its ldf completed) and is immediately re-used by the second ldf of the loop. The second ldf reads r1 from the Map Table — which now points at RS#1 (the in-flight addi) — so this RS captures T2 = RS#1 as a tag instead of a value, and the Map Table entry for f1 is overwritten with RS#2 again. (This is a WAW situation: the original first ldf already wrote f1 and is gone, but if it had still been pending, the rename here would have just replaced its tag — no stall, no wait. That’s the key point.) mulf is now executing (X=c5) with V1=[f0], V2=[f1]. addi issues with V1=[r1] and goes to the ALU.
Tomasulo: Cycle 6
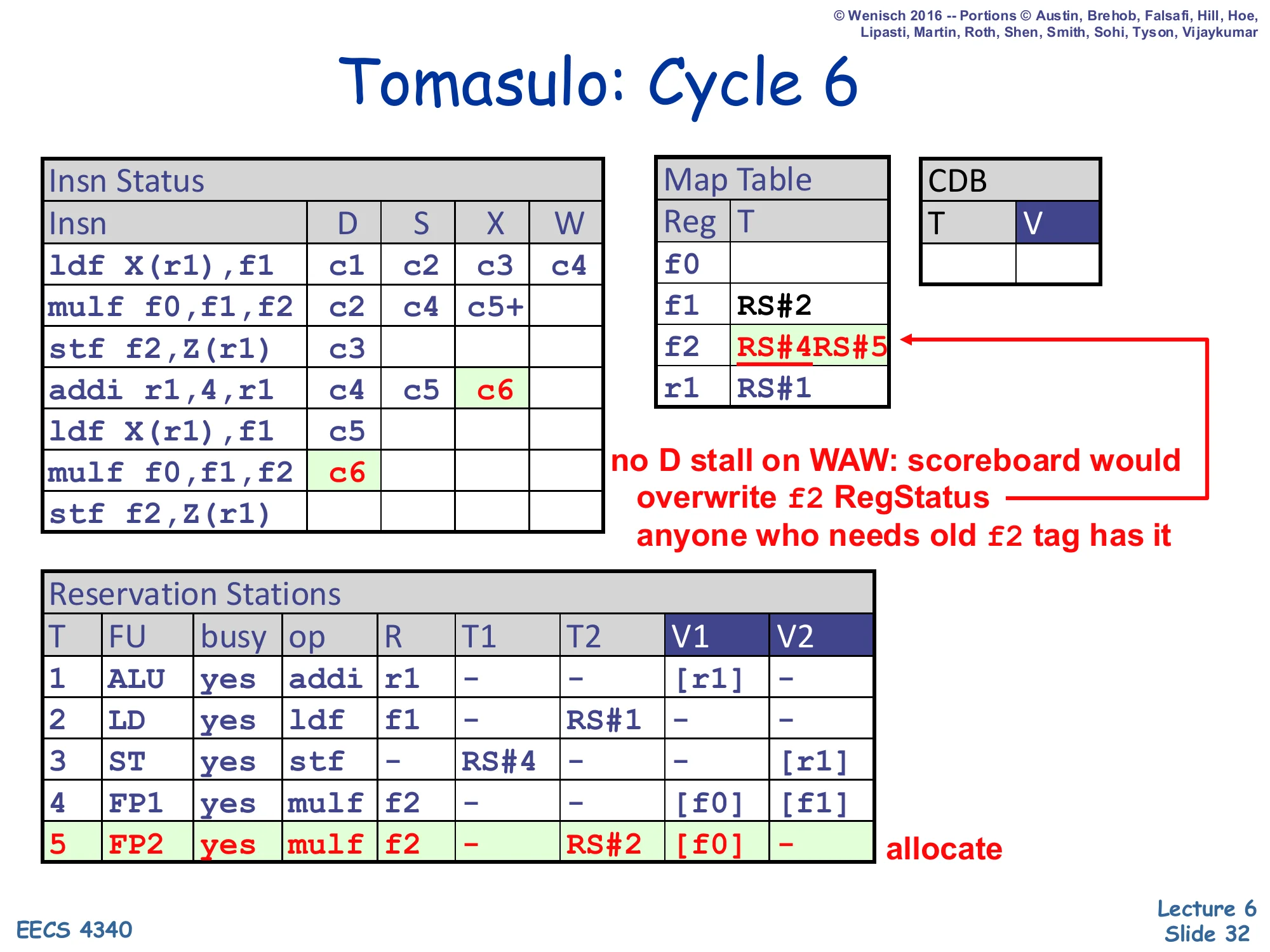
Show slide text
Tomasulo: Cycle 6
- Insn Status:
addiX=c6; secondmulf f0,f1,f2D=c6. - Map Table:
f1→RS#2,f2→ RS#4 → RS#5,r1→RS#1. - RS#5 (FP2): allocate (busy=yes, op=mulf, R=f2, T2=RS#2, V1=
[f0]).
no D stall on WAW: scoreboard would, anyone who needs old f2 tag has it.
This cycle is the textbook demonstration of why Tomasulo is faster than scoreboarding. The second mulf writes f2, but f2 already has a producer in flight (RS#4) — that is a WAW hazard against the still-executing first mulf. In scoreboarding this would stall dispatch until the first mulf writes back. In Tomasulo dispatch proceeds: the Map Table tag for f2 is simply overwritten from RS#4 to RS#5, and any consumer that had already captured RS#4 (such as RS#3, the still-waiting first stf) is unaffected because it captured the tag, not the entry, and will still grab the right value when RS#4 broadcasts. The annotation makes this explicit: “anyone who needs old f2 tag has it.” The new mulf itself has T2=RS#2 (waiting for the second ldf’s result) and V1=[f0] (read directly), so it can begin watching the CDB in cycle 7.
Tomasulo: Cycle 7
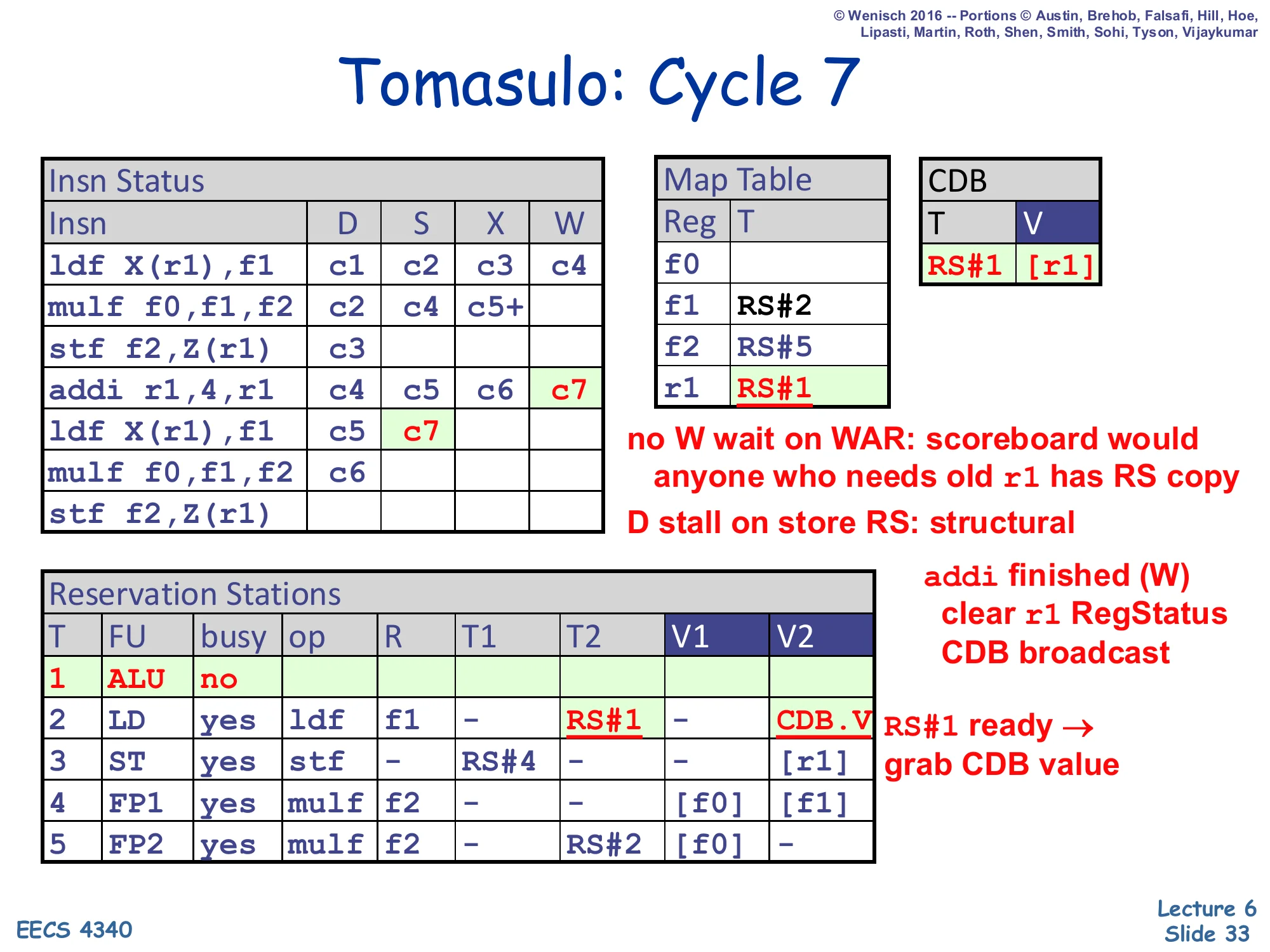
Show slide text
Tomasulo: Cycle 7
- Insn Status:
addiW=c7; secondldfS=c7. - CDB: T=RS#1, V=
[r1](new r1). - Map Table:
f1→RS#2,f2→RS#5,r1→ RS#1 cleared. - RS#1 (ALU): no (free). RS#2 (LD): T2=RS#1 → CDB.V (grab). RS#3 (ST): T1=RS#4 still pending; D stall on store RS structural.
no W wait on WAR; D stall on store RS: structural. addi finished (W) → clear r1 RegStatus, CDB broadcast.
addi writes back: CDB broadcasts ⟨RS#1, new r1⟩, the Map Table entry for r1 is cleared, the regfile is updated. RS#2 (the second ldf) was waiting on T2=RS#1, so it snarfs the new r1 value and becomes ready — issuing the same cycle. The annotation “no W wait on WAR” is the point of the slide: the older first stf in RS#3 still needs the old r1 value (already captured at dispatch as [r1] — V2 contains the old value, not a tag), and addi’s writeback can proceed without waiting for it. In scoreboarding this exact WAR would have blocked addi writeback for many cycles. The other annotation, “D stall on store RS: structural,” foreshadows that the second stf cannot dispatch this cycle because the only ST RS (RS#3) is still occupied by the first store — that is a real structural hazard, unrelated to renaming.
Tomasulo: Cycle 8
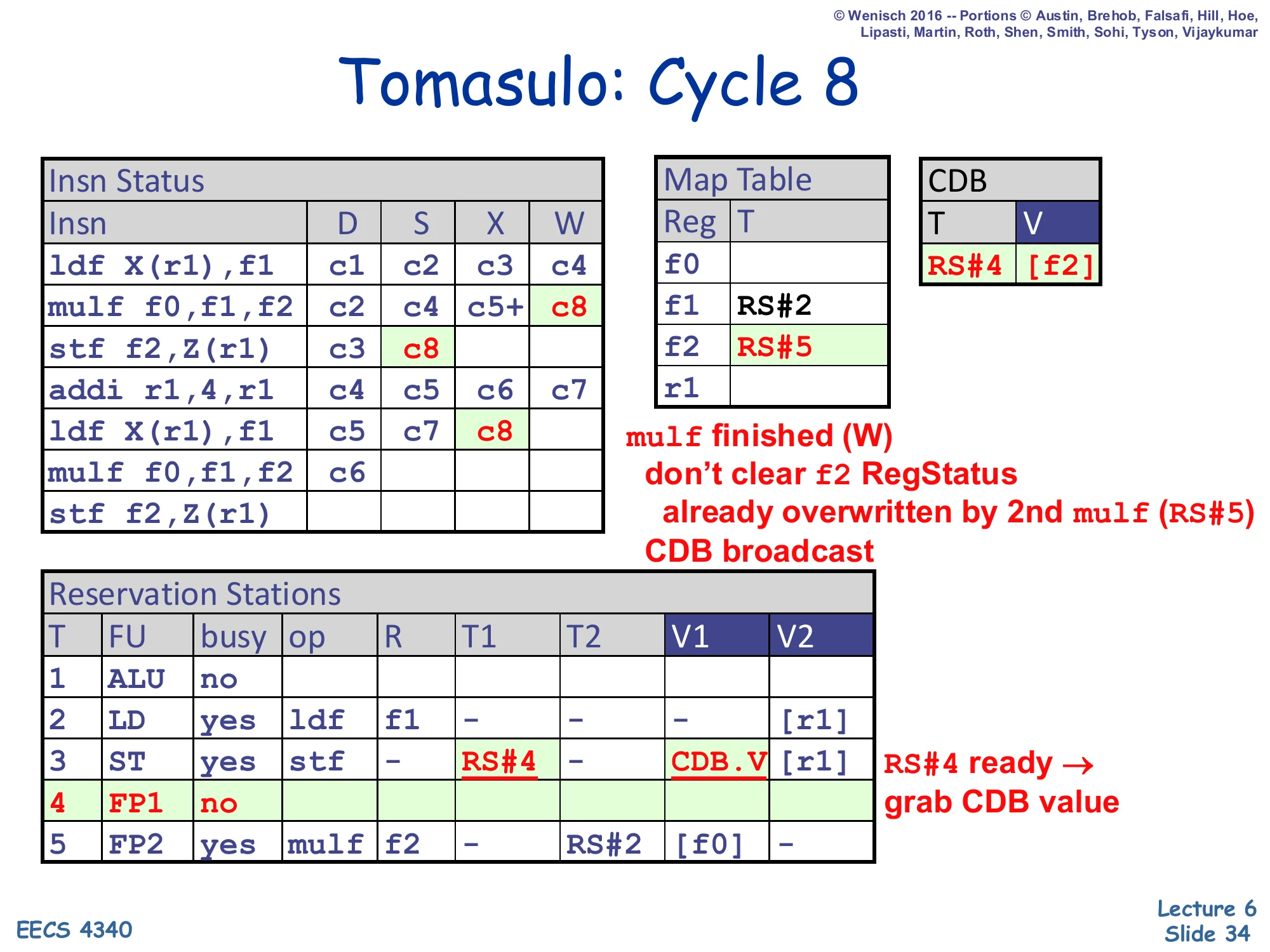
Show slide text
Tomasulo: Cycle 8
- Insn Status:
mulf(1st) W=c8; secondldfX=c8. - CDB: T=RS#4, V=
[f2]. - Map Table:
f1→RS#2,f2→RS#5 (unchanged). - RS#3 (ST): T1=RS#4 → CDB.V (grab). RS#4 (FP1): no.
mulf finished (W); don’t clear f2 RegStatus — already overwritten by 2nd mulf (RS#5). CDB broadcast. RS#4 ready → grab CDB value.
The first mulf writes back its result. The CDB broadcasts ⟨RS#4, [f2]⟩. RS#3 (the first stf) was waiting on T1=RS#4, so it grabs the value into V1 and becomes ready. The crucial subtlety is in the Map Table: f2’s entry currently holds RS#5 (from cycle 6), not RS#4. The writeback logic compares its own tag (RS#4) against the Map Table tag (RS#5) — no match — so the regfile write is suppressed and the Map Table is not cleared. If we naively wrote the regfile we would commit a stale value of f2 and lose the fact that RS#5 is the up-to-date producer. This is the signature behavior of value-based renaming under WAW: the older producer’s CDB broadcast still propagates to consumers that captured its tag (RS#3 here), but its master regfile update is silently dropped. Memorize the comparison rule on slide 22: “Output Reg Status tag still matches?”.
Tomasulo: Cycle 9
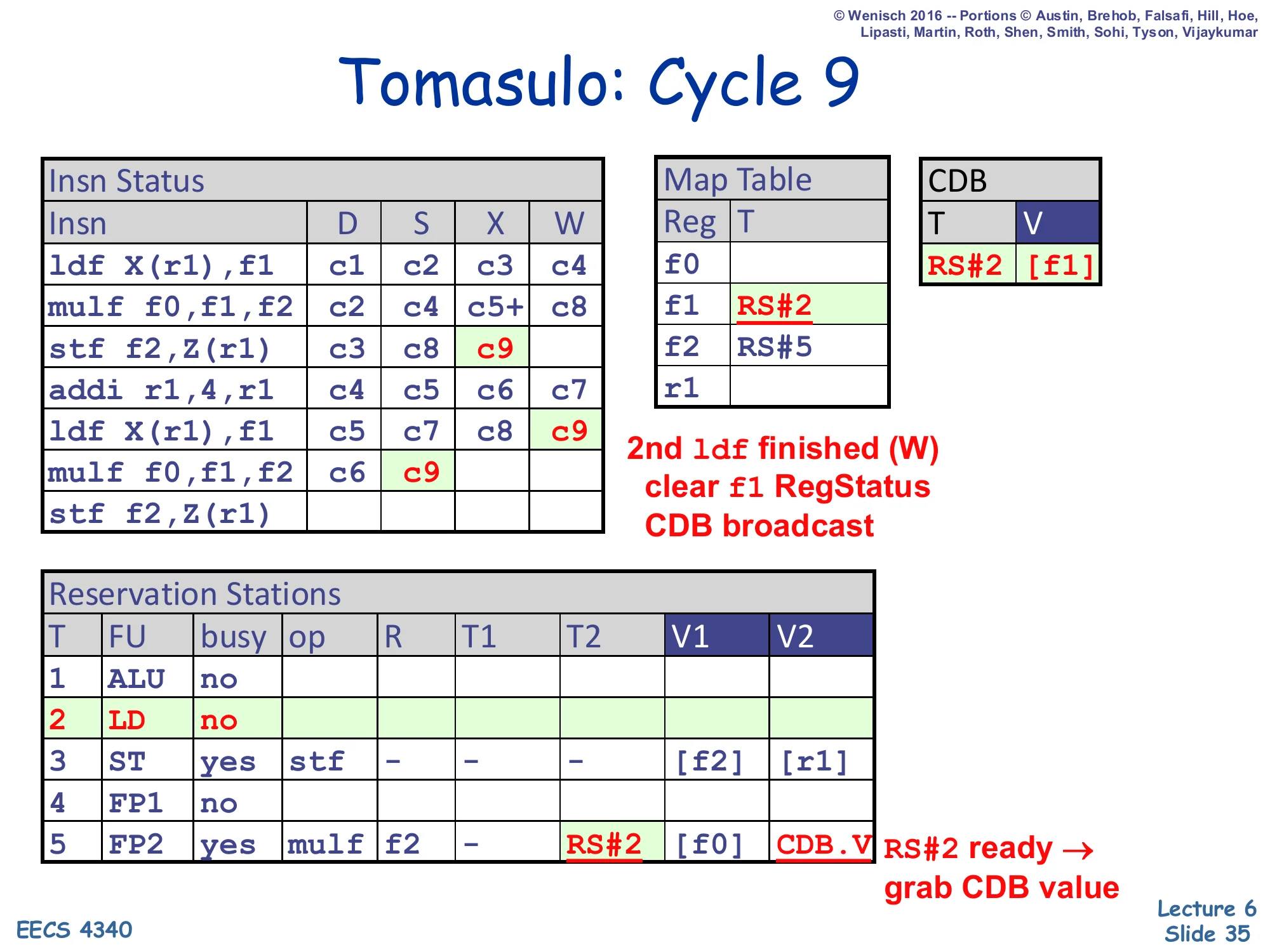
Show slide text
Tomasulo: Cycle 9
- Insn Status: 1st
stfS=c9; 2ndldfW=c9; 2ndmulfS=c9. - CDB: T=RS#2, V=
[f1]. - Map Table:
f1→RS#2 cleared;f2→RS#5. - RS#2 (LD): no (free). RS#3 (ST): V1=
[f2], V2=[r1]. RS#5 (FP2): T2=RS#2 → CDB.V (grab).
2nd ldf finished (W) → clear f1 RegStatus. CDB broadcast. RS#2 ready → grab CDB value.
Three pipelined events fire. (1) The second ldf writes back: CDB ⟨RS#2, [f1]⟩, Map Table f1 cleared, regfile updated. (2) The second mulf (in RS#5) was waiting on T2=RS#2, snarfs the value, and issues to FP2. (3) The first stf finally issues now that V1 was filled in cycle 8 — the lecture pipeline collapses S+X for stores so it ships to memory directly. Notice the reservation station turnover: RS#2 has now hosted both ldfs in the trace and is empty again, ready for slide 36’s reuse pattern. The end-of-cycle Insn Status table shows that even with 5 RS slots and only one of each non-FP unit, two iterations of the loop have substantial overlap — the second iteration’s ldf and mulf are in flight while the first iteration’s stf is just issuing.
Tomasulo: Cycle 10
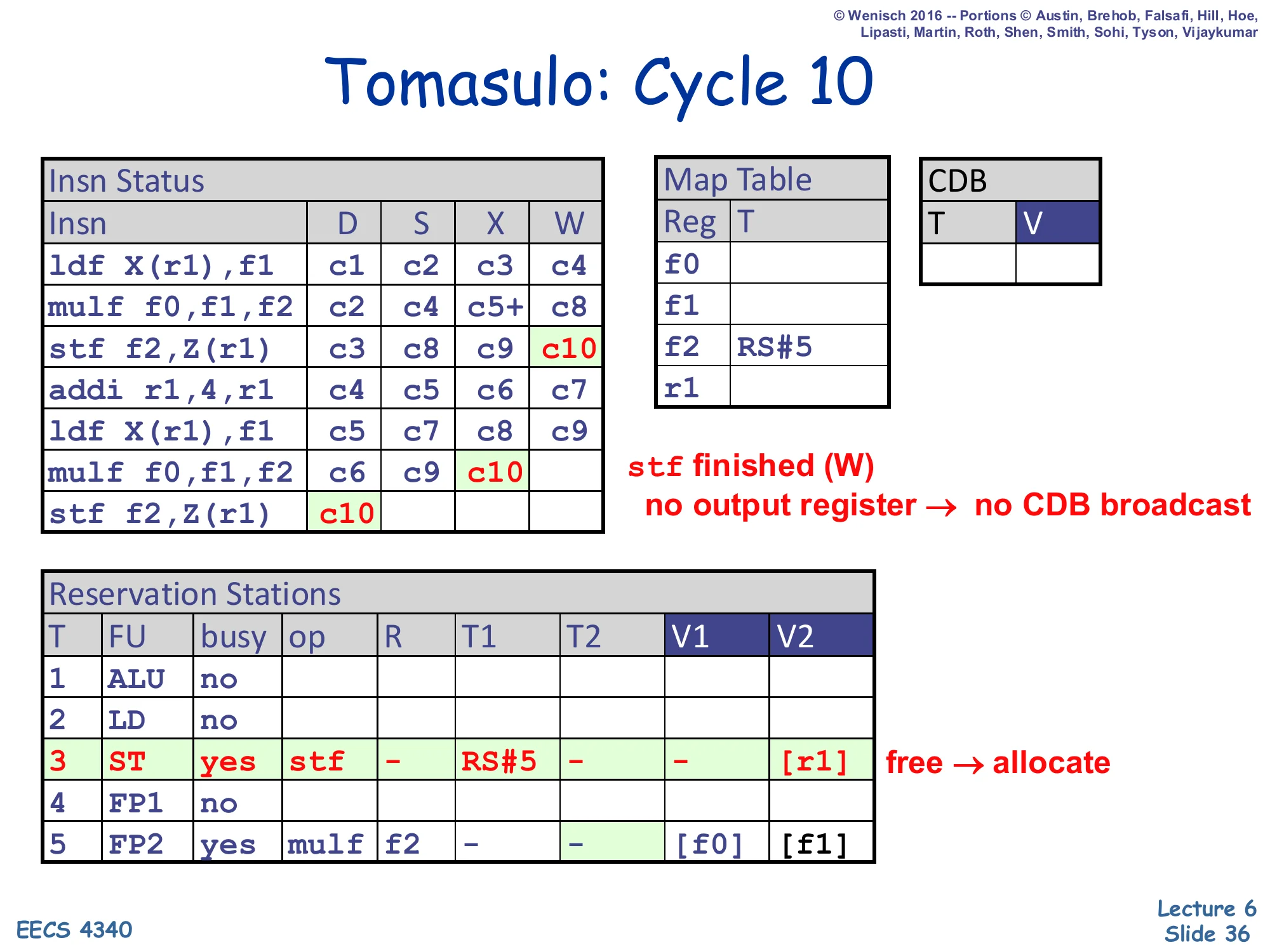
Show slide text
Tomasulo: Cycle 10
- Insn Status: 1st
stfW=c10; 2ndmulfX=c10; 2ndstf f2,Z(r1)D=c10. - Map Table: only
f2→RS#5 still set. - RS#3 (ST): free → allocate (op=stf, T1=RS#5, V2=
[r1]).
stf finished (W) — no output register → no CDB broadcast. ST RS free → allocate.
The first stf writes back (i.e., the cache write retires) and frees RS#3. Stores have no architectural destination, so writeback does not drive the CDB (the slide annotation “no output register → no CDB broadcast”). RS#3 is immediately reallocated to the second stf f2,Z(r1) which had been blocked since cycle 7 by the structural hazard. The new RS#3 captures T1=RS#5 (the second mulf, currently executing) and V2=[r1] (the new r1 value, since the Map Table tag for r1 is empty — addi already wrote back in c7). When RS#5 broadcasts in a later cycle, this stf will grab the value and execute. This cycle closes the worked example: by c10 we have started both iterations and committed three of the seven instructions, with the others still pipelined through the FUs.
Scoreboard vs. Tomasulo
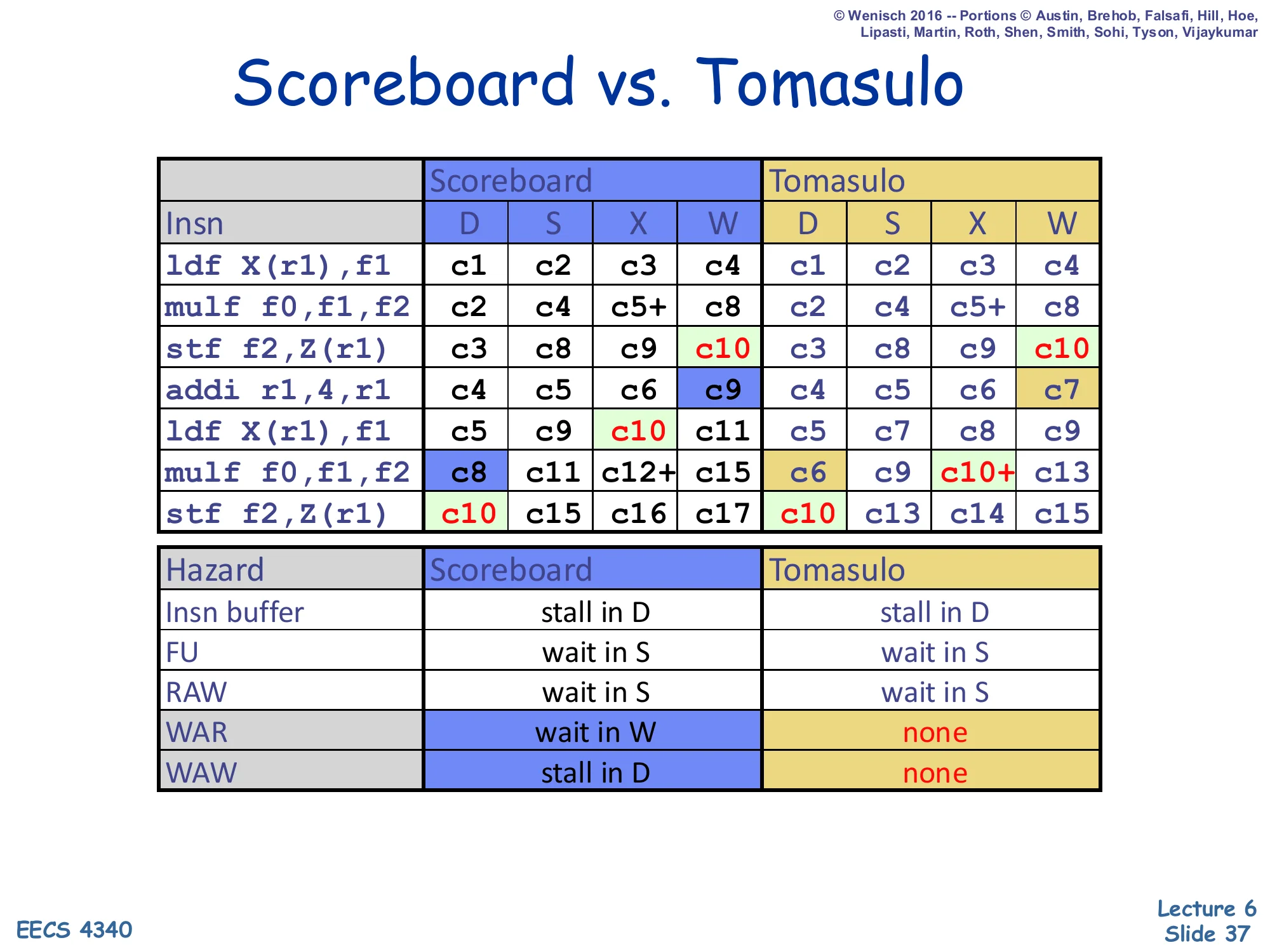
Show slide text
Scoreboard vs. Tomasulo
| Insn | Scoreboard D | S | X | W | Tomasulo D | S | X | W |
|---|---|---|---|---|---|---|---|---|
ldf X(r1),f1 | c1 | c2 | c3 | c4 | c1 | c2 | c3 | c4 |
mulf f0,f1,f2 | c2 | c4 | c5+ | c8 | c2 | c4 | c5+ | c8 |
stf f2,Z(r1) | c3 | c8 | c9 | c10 | c3 | c8 | c9 | c10 |
addi r1,4,r1 | c4 | c5 | c6 | c9 | c4 | c5 | c6 | c7 |
ldf X(r1),f1 | c5 | c9 | c10 | c11 | c5 | c7 | c8 | c9 |
mulf f0,f1,f2 | c8 | c11 | c12+ | c15 | c6 | c9 | c10+ | c13 |
stf f2,Z(r1) | c10 | c15 | c16 | c17 | c10 | c13 | c14 | c15 |
| Hazard | Scoreboard | Tomasulo |
|---|---|---|
| Insn buffer | stall in D | stall in D |
| FU | wait in S | wait in S |
| RAW | wait in S | wait in S |
| WAR | wait in W | none |
| WAW | stall in D | none |
The numerical comparison crystallizes the win. Both schemes finish the first three instructions in identical cycles — there are no false dependences to disambiguate, only RAWs. The difference shows up at addi: scoreboarding’s W slips to c9 because of the WAR on r1; Tomasulo’s W happens at c7 because there is no WAR. That two-cycle improvement cascades through the second iteration: second ldf completes c11 vs. c9, second mulf completes c15 vs. c13, second stf completes c17 vs. c15. The bottom table is the canonical exam summary — memorize all five rows. The takeaways are clean: the same hazards that stall dispatch or wait at issue in both schemes are unchanged; only WAR (which scoreboarding handles by waiting in W) and WAW (which scoreboarding handles by stalling in D) become non-issues under Tomasulo.
Scoreboard vs. Tomasulo II: Cache Miss
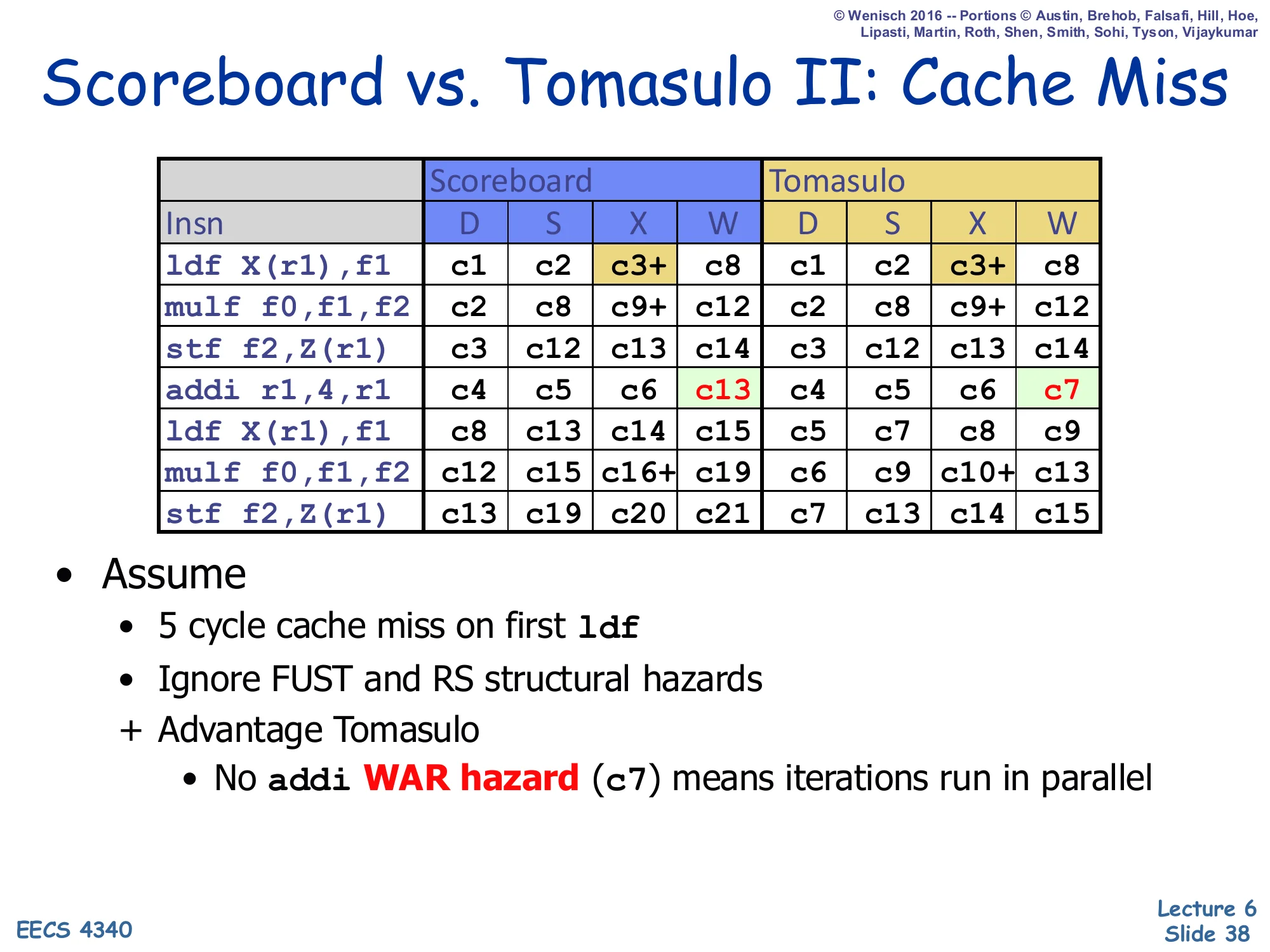
Show slide text
Scoreboard vs. Tomasulo II: Cache Miss
| Insn | Scoreboard D | S | X | W | Tomasulo D | S | X | W |
|---|---|---|---|---|---|---|---|---|
ldf X(r1),f1 | c1 | c2 | c3+ | c8 | c1 | c2 | c3+ | c8 |
mulf f0,f1,f2 | c2 | c8 | c9+ | c12 | c2 | c8 | c9+ | c12 |
stf f2,Z(r1) | c3 | c12 | c13 | c14 | c3 | c12 | c13 | c14 |
addi r1,4,r1 | c4 | c5 | c6 | c13 | c4 | c5 | c6 | c7 |
ldf X(r1),f1 | c5 | c13 | c14 | c15 | c5 | c7 | c8 | c9 |
mulf f0,f1,f2 | c8 | c14 | c15+ | c18 | c6 | c9 | c10+ | c13 |
stf f2,Z(r1) | c13 | c19 | c20 | c21 | c7 | c13 | c14 | c15 |
- Assume
- 5 cycle cache miss on first
ldf - Ignore FUST and RS structural hazards
- 5 cycle cache miss on first
-
- Advantage Tomasulo
- No
addiWAR hazard (c7) means iterations run in parallel
The cache-miss study amplifies the gap. With a 5-cycle cache miss on the first ldf, both schedulers see the same slowdown on the dependence chain (mulf/stf of iteration 1). But the iteration-2 instructions are independent of f1 from iteration 1, and Tomasulo’s lack of WAR hazards lets them slip past in parallel: addi completes at c7 (vs. c13 in scoreboarding), the second iteration’s ldf issues at c7 (vs. c13), and the second stf retires at c15 vs. c21 — a six-cycle savings on a workload of seven instructions. The important conceptual takeaway is highlighted in red on the slide: false-dependence elimination unlocks parallelism between iterations even when the in-iteration dependences remain serial. This is the canonical motivation for combining Tomasulo-style renaming with hardware prefetching and aggressive memory pipelines in modern out-of-order processors.
Can We Add Superscalar?

Show slide text
Can We Add Superscalar?
- Dynamic scheduling and multiple issue are orthogonal
- E.g., Pentium4: dynamically scheduled 5-way superscalar
- Two dimensions
- N: superscalar width (number of parallel operations)
- W: window size (number of reservation stations)
- What do we need for an N-by-W Tomasulo?
- RS: N tag/value w-ports (D), 2N value r-ports (S), 2N tag CAMs (W)
- Select logic: W → N priority encoder (S)
- MT: 2N r-ports (D), N w-ports (D)
- RF: 2N r-ports (D), N w-ports (W)
- CDB: N (W)
- Which are the expensive pieces?
Tomasulo and superscalar are orthogonal: any scheduler can be widened to issue N instructions per cycle. The cost analysis here is a port-counting exercise. The N-by-W Tomasulo needs N writes per cycle into the RS (one per dispatched insn × tag/value pair), 2N value reads per cycle out of the RS (for issue), and 2N tag CAMs across all W RS entries (for CDB matching). Map Table and Regfile each take 2N read ports for dispatch (each insn reads two sources) and N write ports — for the MT during dispatch (renaming destinations) and for the RF during writeback (master commit). The CDB itself widens to N broadcast wires. The exam-relevant takeaway is which scale super-linearly: the W → N select logic (priority encoder) is roughly N2logW — slide 40 will discuss how to keep this manageable. Multi-port SRAMs for MT and RF are the other costly piece; CAM tag matching scales linearly in W * N.
Superscalar Select Logic

Show slide text
Superscalar Select Logic
- Superscalar select logic: W → N priority encoder
- Somewhat complicated (N2logW)
- Can simplify using different RS designs
- Split design
- Divide RS into N banks: 1 per FU?
- Implement N separate W/N → 1 encoders
-
- Simpler: N⋅log(W/N)
- – Less scheduling flexibility
- FIFO design [Palacharla+]
- Can issue only head of each RS bank
-
- Simpler: no select logic at all
- – Less scheduling flexibility (but surprisingly not that bad)
The select-logic problem is to pick N ready RS entries out of W candidates each cycle, and the naive N2logW priority encoder is one of the highest-power, longest-latency structures in a wide out-of-order core. Two well-known simplifications: (1) the split design partitions the RS into N per-FU banks of W/N entries; each bank has its own simple W/N → 1 encoder so the global fanout drops from N2logW to Nlog(W/N), at the cost of “steering” instructions to specific banks at dispatch and losing the ability for any FU to pick up any ready instruction. (2) The FIFO design (Palacharla, Jouppi, Smith) takes this further: each bank is a FIFO and the head is the only candidate, so there is no select logic at all. The surprise of the Palacharla paper is that on real workloads the FIFO design loses very little IPC because dependence chains naturally serialize across instructions anyway — a counterintuitive result that influenced many subsequent micro-architectures.
Can We Add Bypassing?
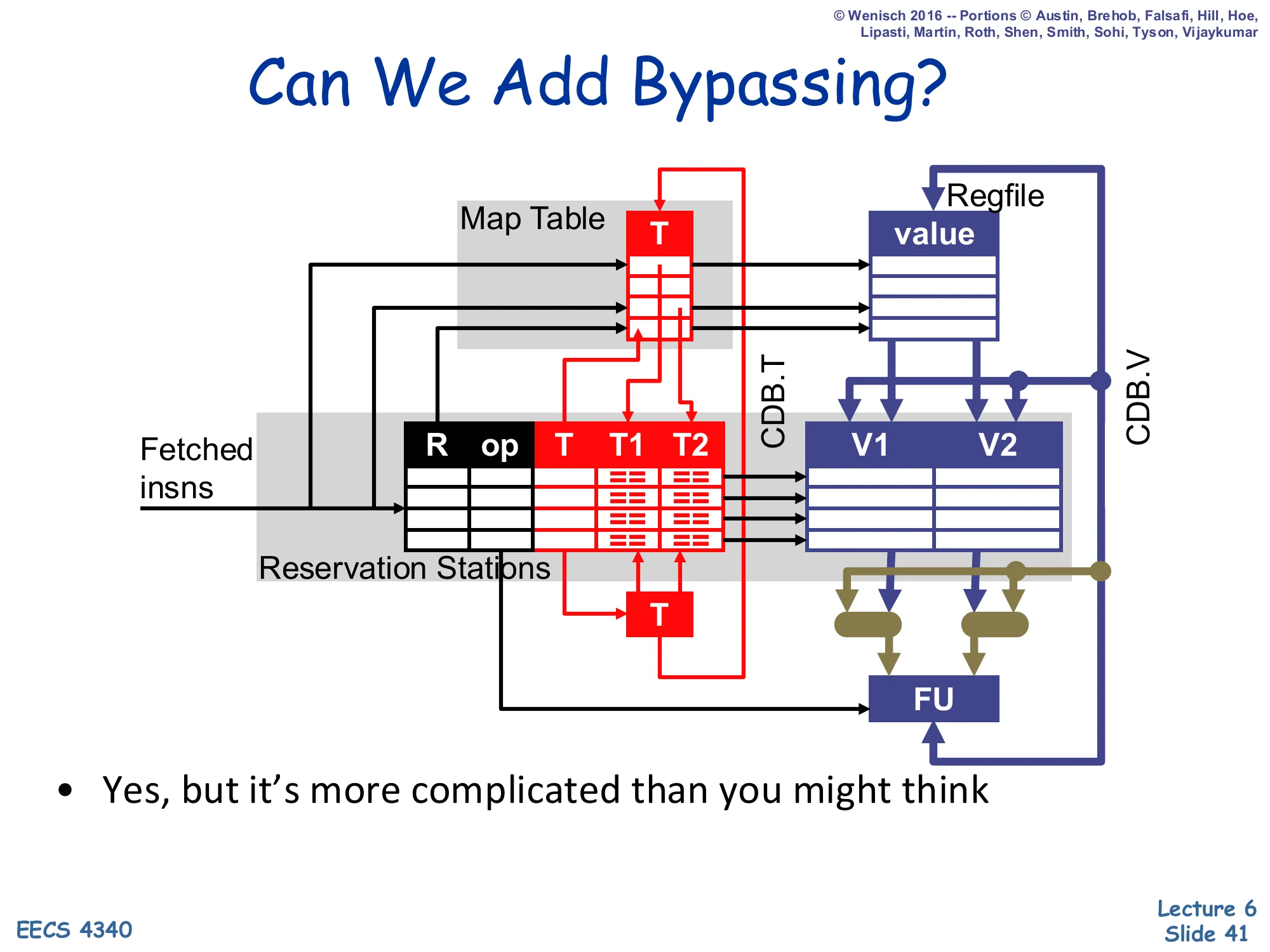
Show slide text
Can We Add Bypassing?
Diagram: Map Table (T), Reservation Stations (R, op, T, T1, T2), Regfile (value), V1/V2, with new bypass network from FU output back into V1/V2 muxes — green wires.
- Yes, but it’s more complicated than you might think
Simple Tomasulo deliberately omitted bypassing for an apples-to-apples comparison with scoreboarding, but real Tomasulo machines (including the IBM 360/91 itself) need it: without bypassing, dependent instructions must wait for the producer to complete, win the CDB, and then go through the next-cycle issue, costing at least one extra cycle per dependency edge. Adding bypassing means muxing FU outputs directly into V1/V2 in time for the next cycle’s issue. The slide warns this is harder than it looks, and the next slide explains why: you must split the CDB tag broadcast (which schedules dependents) from the CDB value delivery (which feeds them), because in a bypassing schedule the dependent must issue in the cycle the producer completes, before the producer’s value is even on the CDB.
Why Out-of-Order Bypassing Is Hard
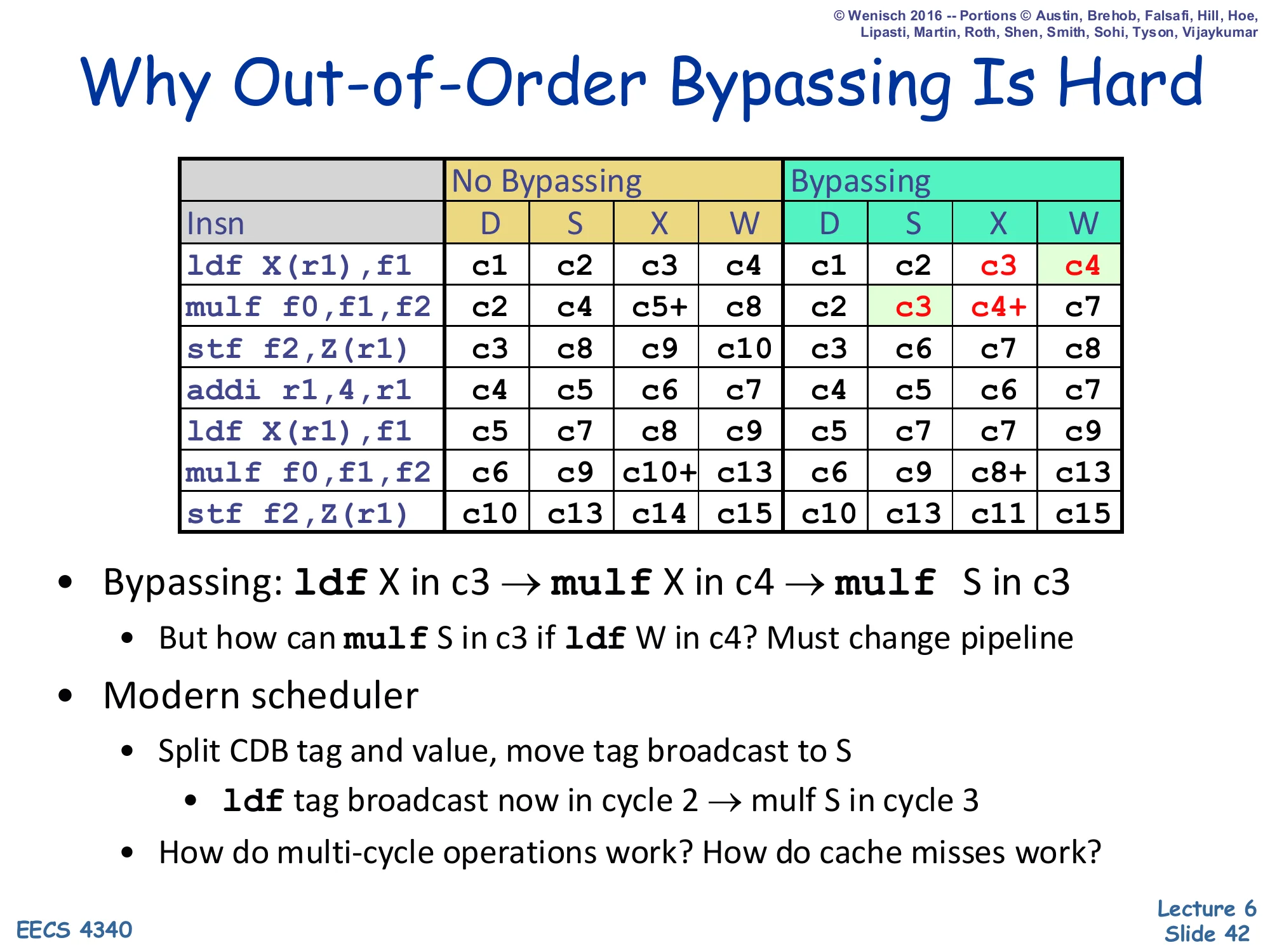
Show slide text
Why Out-of-Order Bypassing Is Hard
| Insn | No Bypass D | S | X | W | Bypass D | S | X | W |
|---|---|---|---|---|---|---|---|---|
ldf X(r1),f1 | c1 | c2 | c3+ | c8 | c1 | c2 | c3+ | c4 |
mulf f0,f1,f2 | c2 | c8 | c9+ | c12 | c2 | c3 | c4+ | c7 |
stf f2,Z(r1) | c3 | c12 | c13 | c14 | c3 | c8 | c9 | c10 |
addi r1,4,r1 | c4 | c5 | c6 | c7 | c4 | c5 | c6 | c7 |
ldf X(r1),f1 | c5 | c7 | c8 | c9 | c5 | c7 | c8 | c9 |
mulf f0,f1,f2 | c6 | c9 | c10+ | c13 | c6 | c8+ | c9+ | c13 |
stf f2,Z(r1) | c7 | c13 | c14 | c15 | c10 | c13 | c14 | c15 |
- Bypassing:
ldfX in c3 →mulfX in c4 →mulfS in c3- But how can
mulfS in c3 ifldfW in c4? Must change pipeline
- But how can
- Modern scheduler
- Split CDB tag and value, move tag broadcast to S
ldftag broadcast now in cycle 2 →mulfS in cycle 3
- How do multi-cycle operations work? How do cache misses work?
- Split CDB tag and value, move tag broadcast to S
The puzzle: a one-cycle producer like ldf (X=c3) should let a dependent mulf execute in c4 — meaning mulf must issue in c3, the same cycle the producer is still in execute. But in classical Tomasulo, the dependent only sees the producer’s value via the CDB at writeback (c4). The clever fix is to split the CDB into a tag-broadcast wire (signals “about to be ready next cycle”) and a value wire (carries the actual value one cycle later, in time for bypassing into the FU input). Push the tag broadcast back to S (issue) of the producer, two cycles before W. Then the dependent’s RS becomes ready at the producer’s S (cycle 2 here), the dependent issues at cycle 3, and the value arrives via bypass in cycle 4 — perfectly aligned. This restructuring is universal in modern schedulers; it complicates handling of variable-latency events (multi-cycle FPs and especially cache misses, which require replay mechanisms when the predicted latency proves wrong) — topics for the next lectures.
Dynamic Scheduling Summary

Show slide text
Dynamic Scheduling Summary
- Dynamic scheduling: out-of-order execution
- Higher pipeline / FU utilization, improved performance
- Easier and more effective in hardware than software
-
- More storage locations than architectural registers
-
- Dynamic handling of cache misses
-
- Instruction buffer: multiple F/D latches
- Implements large scheduling scope + “passing” functionality
- Split decode into in-order dispatch and out-of-order issue
- Stall vs. wait
- Dynamic scheduling algorithms
- Scoreboard: no register renaming, limited out-of-order
- Tomasulo: copy-based register renaming, full out-of-order
The wrap-up slide. Dynamic scheduling improves performance because hardware sees runtime information that the compiler cannot — most importantly, cache miss vs. hit decisions and dynamic register-pressure relief from a much larger physical storage pool than the ISA exposes. The implementation invariant is the instruction buffer sandwiched between fetch and issue, holding many fetched-but-not-yet-issued instructions and supporting the “passing” semantics that let independent younger instructions execute first. The critical conceptual move is splitting decode into in-order dispatch (which renames and allocates) and out-of-order issue (which fires when ready) — together with the stall vs. wait distinction that lets the front end keep up while the back end re-orders. The two algorithms covered: scoreboarding gives partial out-of-order without renaming and pays for it in WAR/WAW hazards; Tomasulo adds copy-based register renaming and reservation stations to achieve fully out-of-order execution at the cost of CAM-style operand snarfing on the CDB.
Are we done?

Show slide text
Are we done?
- When can Tomasulo’s algorithm go wrong?
- Exceptions!!
- No way to figure out the relative order of instructions in RS
- Lack of instructions to choose from!!
- Need a great branch predictor
- Exceptions!!
- Next Lecture: How to make exceptions work
Two unsolved problems remain. The first is exceptions: when a divide-by-zero or page fault occurs in the middle of an out-of-order schedule, Tomasulo has no record of program order — the architectural register file holds whatever the most recent broadcasts have written, which may be from instructions both earlier and later than the faulting one. There is no way to roll back to the ISA-defined precise architectural state at the faulting PC. The fix introduced in L07 is the reorder buffer (ROB), which stores in-flight instructions in program order and commits them sequentially, supporting precise interrupts. The second problem is the supply side: the scheduler can only reorder instructions it has fetched, and conditional branches limit how far ahead the front end can fetch. Solving this requires aggressive branch prediction (L10–L11) so that speculative execution keeps the RS full of useful work.
Readings

Show slide text
Readings
For today:
- H & P Chapter 3.4–3.6
- Design Space of Register Renaming Techniques, https://ieeexplore.ieee.org/abstract/document/877952
For next Wednesday:
- H & P Chapter 3.8–3.9, C.4–C.5
- Implementing precise interrupts in pipelined processors, https://ieeexplore.ieee.org/abstract/document/4607
- H & P Chapter 3.13
Announcements

Show slide text
Announcements
- Lab #5 next Monday
- Project #3
- Due: 25-Feb-26
- Project #4
- Due: proposal, 4-Mar-26
- More details in today’s class
- Mid-term exam
- 9-Mar-26